F# & NServiceBus - praktyczny przewodnik: Wprowadzenie
Posty z tej serii:
- F# & NServiceBus - praktyczny przewodnik: Wprowadzenie
- F# & NServiceBus - praktyczny przewodnik: Konfiguracja Endpointa
- F# & NServiceBus - praktyczny przewodnik: Wysłanie komendy
- F# & NServiceBus - praktyczny przewodnik: Komunikacja wielu Endpointów
- F# & NServiceBus - praktyczny przewodnik: Publikowanie zdarzeń
- F# & NServiceBus - praktyczny przewodnik: Zarządzanie procesem biznesowym - Saga
- F# & NServiceBus - praktyczny przewodnik: Zakończenie
Kiedy siadasz do napisania kawałka funkcjonalności, czy zadajesz sobie pytanie, w jaki sposób ułożyć kod, aby daną funkcjonalność zrealizować? Pisząc w paradygmacie obiektowym, zastanawiasz się, ile klas utworzyć? Jakie powinny być powiązania pomiędzy poszczególnymi klasami? Jaki rozmiar powinna mieć klasa, żeby kod w niej zawarty był łatwy w utrzymaniu, a także gotowy na ewentualne przyszłe zmiany? Zgaduję, że w 90% na wszystkie te pytania odpowiedź brzmi TAK. Dwie najbardziej popularne techniki, które pomogą Ci w podjęciu decyzji i wyborze rozwiązania to Wzorce projektowe oraz zasady SOLID. Na wyższym poziomie projektowania będą to Wzorce aplikacyjne. W moim przypadku okazywały się one bardzo skuteczne. O kilku z nich pisałem w artykule Wytwarzanie oprogramowania II - techniki programowania.
Kodując rozwiązania w takim podejściu, zawsze jednak towarzyszyła mi niewytłumaczalna myśl, że “Coś jednak tu nie pasuje?”. Punktem kulminacyjnym była sytuacja, kiedy zaprojektowałem rozwiązanie, które bardzo mocno opierało się na dwóch zasadach SOLID: Single Responsibility Principle (SRP) oraz Interface Segregation Principle (ISP). W pewnym momencie okazało się, że klasa odpowiedzialna za realizację pewnej funkcjonalności, posiada około dziesięciu, albo i więcej, zależności do zewnętrznych interfejsów. Przykład w pseudo kodzie:
public class Z : IZ
{
private readonly IA a;
//...
private readonly IJ a;
public Z(IA a, IB b, IC c, ID d, IE e, IF f, IG g, IH h, II i, IJ j)
{
this.a = a
//...
this.j = j
}
public var Calculate()
{
// get values
var a = this.a.GetA(...);
var b = this.b.GetB(...);
// ...
var j = this.j.GetJ(...);
// calculate and return result based on values getting from interfaces
}
//...
}To jeszcze samo w sobie nie było złe, ale gdy przyszło do napisania testów jednostkowych dla jednej z metod tej klasy (przykładowa metoda Calculate()), trzeba było zafakeować/zastubować zachowanie wszystkich interfejsów, aby móc przetestować jej logikę. Paradoksalnie logika była dość prosta, ale do poprawnego działania potrzebowała danych pochodzących z implementacji każdego z interfejsów. Ostatecznie 80% kodu było fakeowaniem zwracanych danych, a tylko 20% testowaniem logiki wraz z asercjami. Wtedy to właśnie dostałem odpowiedź na swoje pytanie “Coś jednak tu nie pasuje?”. Całość wydawała mi się przekombinowana. Przykład testu w pseudokodzie:
using NUnit.Framework;
[TestFixture]
public class ZTests
{
private readonly IA a;
//...
private readonly IJ j;
[Test]
public void T()
{
// Arrange
var z = this.GetZ();
// use favorite tool to fake this.a.GetA(...) result
// use favorite tool to fake this.b.GetB(...) result
// use favorite tool to fake this.c.GetC(...) result
// use favorite tool to fake this.d.GetD(...) result
// use favorite tool to fake this.e.GetE(...) result
// use favorite tool to fake this.f.GetF(...) result
// use favorite tool to fake this.g.GetG(...) result
// use favorite tool to fake this.h.GetH(...) result
// use favorite tool to fake this.i.GetI(...) result
// use favorite tool to fake this.j.GetJ(...) result
// Act
var result = z.Calculate();
// Assert
// check result
}
private Z GetZ()
{
this.a = // use favorite tool to create fake object
this.b = // use favorite tool to create fake object
//...
this.j = // use favorite tool to create fake object
return new Z(this.a, /*...*/, this.j);
}
}Poszukiwanie odpowiedzi na pytanie “Czy można inaczej?” nakierowało mnie na funkcyjne podejście do konstruowania kodu. Okazało się, że rozwiązaniem byłoby wydzielenie logiki do osobnej metody, która w parametrach przyjmowałaby tylko wartości, niezbędne do policzenia i zwrócenia wyniku. W ten sposób zadaniem metody Calculate() byłoby pobranie danych z implementacji interfejsów, następnie wywołanie metody Calculate(a,b,…,j) z odpowiednimi parametrami, a na końcu dalsze procesowanie zwróconego wyniku. Jest to eleganckie zastosowanie zasady Single Responsibility Principle na poziomie metod w klasie, a nie samych klas. Przykład w pseudokodzie:
public var Calculate()
{
// get values
var a = this.a.GetA(...);
var b = this.b.GetB(...);
// ...
var j = this.j.GetJ(...);
var result = this.Calculate(a, b, ..., j);
// continue processing result
}
public var Calculate(var a, var b, var c, var d, var e, var f, var g, var h, var i, var j)
{
// calculate and return result based on input parameters
}Test do drugiej metody nie wymagałby żadnego fakeowania, a jedynie przekazania odpowiednich wartości w parametrach metody. Przykład w pseudokodzie:
using NUnit.Framework;
[TestFixture]
public class ZTests
{
private readonly IA a;
//...
private readonly IJ j;
[Test]
public void T()
{
// Arrange
var z = this.GetZ();
var va = valueA;
var vb = valueB;
var vc = valueC;
var vd = valueD;
var ve = valueE;
var vf = valueF;
var vg = valueG;
var vh = valueH;
var vi = valueI;
var vj = valueJ;
// Act
var result = z.Calculate(va, vb, vc, vd, ve, vf, vg, vh, vi, vj);
// Assert
// check result
}
private Z GetZ()
{
this.a = // use favorite tool to create fake object
this.b = // use favorite tool to create fake object
//...
this.j = // use favorite tool to create fake object
return new Z(this.a, /*...*/, this.j);
}
}Piszę to w czasie przypuszczającym, ponieważ na tamten moment nie miałem rozwiązania tego zagadnienia. Kod działał i robił to, co miał robić, a ponieważ terminy goniły to…trzeba było “jechać” dalej z tematami ;)
Programowanie Funkcyjne - podejście nr 1
Programowanie funkcyjne znałem tylko z wykładów i ćwiczeń na studiach. W tamtym czasie konstrukcje funkcyjne były dla mnie dziwne i trochę nieintuicyjne. Rozumiałem stojące za nimi idee, jednak w porównaniu z konstrukcjami obiektowymi, bliżej mi było do tych ostatnich. Dokładnie te same odczucia miałem, próbując na nowo zapoznać się z tematem. Kończyło się tym, że po paru próbach powracałem do tego, co dobrze znam. Potem znowu dawałem sobie szansę na zgłębienie zagadnienia, po to, aby znowu przerwać i zająć się czymś innym. Temat jednak sam do mnie powracał i to w momentach, w których tego nie oczekiwałem. Tak jakby programowanie funkcyjne samo chciało, abym się go nauczył ;) Co więcej, wszystkie elementy zaczęły łączyć się w jedną całość.
Programowanie Funkcyjne - podejście nr 2
Głównym źródłem, z którego czerpałem wiedzę i czerpię do dziś jest strona fsharpforfunandprofit. Zawiera ona mnóstwo artykułów dotyczących programowania oraz projektowania funkcyjnego w języku F#. Programując na co dzień w języku C#, F# był naturalnym wyborem do nauki. Po pierwszym odstawieniu natrafiłem na link do slajdów prezentacji autora strony Scott Wlaschin, pod tytułem Functional Design Patterns. Moją szczególną uwagę przykuł slajd nr 15:

Źródło - Functional Design Patterns
Nastąpił u mnie wtedy tzw. efekt Wow! i myśl w stylu “Czyli jak opanuję konstrukcje funkcyjne, to wszystkie wzorce będę mógł zrealizować za pomocą jednego pojęcia - funkcji!”. Dało mi to nową energię do nauki, jednak po chwili zgasła ona tak jak za pierwszym razem. Powód był ten sam. “Wszystko fajnie, ale dalej mam poczucie robienia 5 kroków w tył. Nie dziękuję, zostaję przy konstruowaniu kodu w sposób obiektowy z wykorzystaniem konstrukcji imperatywnych”.
Programowanie Funkcyjne - podejście nr 3
Jakiś czas potem natrafiłem na link do slajdów prezentacji tego samego autora pod tytułem Domain Driven Design with the F# type System. W tym przypadku moją szczególną uwagę przykuły slajdy nr 12 i 14:

Źródło - Domain Driven Design with the F# type System

Źródło - Domain Driven Design with the F# type System
Efekt? “No tak, obecnie pojęcia ze świata obiektowego są dla mnie znane, ale jak zaczynałem, to przecież ich nie znałem, a kod pisałem! Ten sam wzorzec mogę przecież zastosować do programowania funkcyjnego - zacząć pisać!”
Jak pewnie się domyślasz, zapał trwał chwilę. Po raz kolejny temat odstawiłem na bok.
Programowanie Funkcyjne - podejście nr 4
Czwartym zapalnikiem było natrafienie na bloga Mark Seemann, a zwłaszcza na dwa artykuły. Pierwszy to SOLID: the next step is Functional. Efekt? “No tak prawdziwe SRP jest wtedy, kiedy interfejs posiada tylko jedną metodę!”. Od razu przypomniał mi się przypadek z początku tego artykułu. Klasa miała zależności do 10 interfejsów, ale każdy z tych interfejsów miał po kilka metod oraz zależności do innych interfejsów. Jakby trzymać się restrykcyjnej zasady SRP to klasa ta miałaby zależności do grubo ponad 50 interfejsów!
Drugi artykuł to Dependency rejection. Efekt? “To jest odpowiedź na pytanie, jak unikać fakeowania kodu w testach”, a mianowicie oddzielać części, które mogą być zakodowane jako pure, od części, które muszą być zakodowane jako impure. Do testowania części pure fakei nie są potrzebne. Jeśli chcę testować części impure to wykorzystuję fakei.
Programowanie Funkcyjne - podejście nr 5
Równolegle do kolejnych prób zapoznawania się z konstrukcjami funkcyjnymi, mocno wsiąknąłem we framework NServiceBus oraz filozofię wytwarzania oprogramowania stojącą za tym frameworkiem. O motywach pisałem w artykule Wytwarzanie oprogramowania IV - NServiceBus - framework, który zmienia zasady gry. (Już wiesz, czym zajmowałem się przy kolejnych odstawieniach :)). Jedną z idei Messagingu jest to, aby Handler przetwarzający dany Message był mały oraz wykonywał jedną rzecz. Jest to jak najbardziej zgodne z zasadą Single Responsibility Principle. Co więcej, jak popatrzy się na API frameworka NServiceBus (v.7.1.10) to widać, że interfejs IHandleMessages posiada tylko jedną metodę, więc spełnia definicję restrykcyjnego SRP:
public interface IHandleMessages<T>
{
Task Handle(T message, IMessageHandlerContext context);
}Idąc dalej, sposób przetwarzania danych wygląda tak:
- message przychodzi
- realizowana jest logika
- message wychodzi
Idealnie wpasowuje się to w podejście impure-pure-impure:
- message pobierany jest z kolejki - impure
- realizowana jest logika - pure
- message przesyłany jest na kolejkę - impure
I tak doszliśmy do historii najnowszej :) Obecnie kodując logikę w Handlerach NServiceBusa, stosuję różne podejścia. Czasami funkcjonalność jest tak mała, że całość zamykam w metodzie Handle. Jeśli widzę potencjał do napisania sensownych testów, to stosuję podejście impure-pure-impure, przenosząc logikę do osobnej metody Handlera. Pokuszę się tutaj o stwierdzenie, że w pewnym sensie stosuję elementy podejścia funkcyjnego, mimo że cały czas posługuję się konstrukcjami obiektowymi. Zdarza się też, że pewne elementy wyciągam do osobnego interfejsu, a następnie wstrzykuję Handlerowi zależność do implementacji tego interfejsu - podejście obiektowe.
Piątym i jak na razie najnowszym zapalnikiem, aby ponownie zmierzyć się z konstrukcjami funkcyjnymi są trzy elementy. Pierwszy to pewna obserwacja, a dwa pozostałe to ponownie materiały, na które natrafiłem, przeglądając internet.
Architektura NServiceBusa oparta jest na paradygmacie obiektowym, co jest jak najbardziej naturalne, ponieważ jest to framework stworzony na platformę .NET z wykorzystaniem języka C#. Kiedy piszę coraz to więcej klas reprezentujących poszczególne Messagee oraz klas obsługujących te Messagee dochodzę do wniosku, że sama klasa staje się dość “ciężką” konstrukcją. Wynikiem całego rozwiązania jest bardzo duża liczba plików, ponieważ dobrą praktyką programowania w języku C# jest to, aby każda klasa znajdowała się w osobnym pliku reprezentującym tę klasę. Same klasy są bardzo małe, więc znowu powraca do mnie znana mi już myśl “Coś tutaj nie pasuje?”. Wniosek? A gdyby tak metodę Handle nie traktować jako metodę interfejsu, ale jako osobną funkcję? A gdyby tak klasę reprezentującą Message nie traktować jako klasę, ale jako typ Messagea? Brzmi to jak podejście funkcyjne. Wynikiem takiego podejścia składającego się na ostateczne rozwiązanie byłyby zbiory reprezentujące:
- typy messagey
- funkcje Handle realizujące funkcjonalności
Drugi element to ciekawy wywiad z Sławomirem Sobótką zatytułowany Świadomy Programista. Mocno zaintrygowała mnie końcówka wywiadu. Zdałem sobie sprawę, że ja właśnie postrzegam rozwiązania jako poskładane ze sobą funkcje mające dobrze zdefiniowane wejście i jasno określone wyjście, mimo tego, że programuję w języku C#, który w swoim pierwotnym założeniu jest językiem obiektowym.
Ostatnim elementem jest prezentacja twórcy języka F# Don Syme pod tytułem F# Code I Love. Tak jak w poprzednich materiałach tak i w tej prezentacji istnieją slajdy, które w szczególności przykuły moją uwagę:

Źródło - F# Code I Love
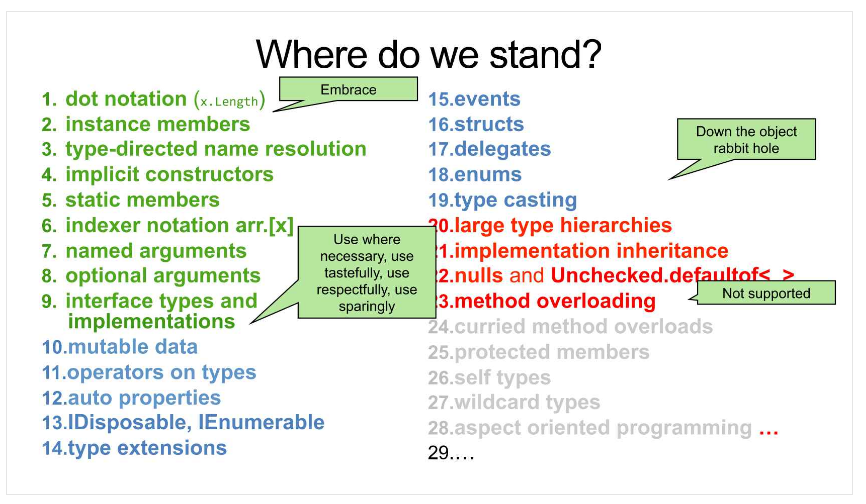
Źródło - F# Code I Love

Źródło - F# Code I Love
Zdałem sobie sprawę, jaka jest przyczyna tego, że nie udaje mi się wytrwać w zapoznawaniu się z programowaniem funkcyjnym. Niesłusznie stosuję metodę zero-jedynkową - “Albo wszystko będę pisał funkcyjnie, albo nie ma sensu zagłębiać się w temat”. Prezentacja ta uświadomiła mi, że wcale nie musi tak być. F# jest językiem funkcyjnym, ale wspiera też elementy obiektowe. Nie ma żadnych przeciwwskazań, aby używać tych drugich, w miejscach, w których wspomogą one realizację rozwiązania. Ważne, aby rozróżniać programowanie obiektowe od programowania zorientowanego obiektowo i ograniczać używanie tego ostatniego jak tylko się da.
Składając wszystko razem w jedną całość, postanowiłem napisać serię artykułów łączących wiedzę na temat mojego ulubionego frameworka NServiceBus z nauką języka F#. Zapraszam Cię do przejścia przez tę serię razem ze mną. Mam nadzieję, że będzie ona dla Ciebie wartościowa.
=