Wytwarzanie oprogramowania IV - NServiceBus - framework, który zmienia zasady gry
Posty z tej serii:
- Wytwarzanie oprogramowania I - paradygmaty programowania
- Wytwarzanie oprogramowania II - techniki programowania
- Wytwarzanie oprogramowania III - architektury systemów informatycznych
- Wytwarzanie oprogramowania IV - NServiceBus - framework, który zmienia zasady gry
Czwarty i zarazem ostatni wpis z tej serii w którym opisuję w jaki sposób można poradzić sobie z powdrożeniowymi problemami awarii w krytycznej części systemu.
No więc wprowadziliśmy zmianę do systemu, wszystkie fazy testów przeszły, zmiana została wdrożona i… przy próbie wprowadzania danych przez użytkowników zaczynają “spływać” błędy. Przykłady:
- nie można złożyć zamówienia towaru
- nie można umówić spotkania na mecz tenisa
- nie można nadać uprawnienia pracownikowi
- …
Przykłady błędów mogą być najróżniejsze:
NullReferenceException;InvalidCastException;TimeoutException;- …
Zanim zaczniemy analizować przyczynę błędów, trzeba przywrócić działanie systemu. Pierwsza myśl jaka przychodzi do głowy to przywrócenie poprzedniej wersji. Ale co jeśli zmiany są łamiące? A co jeśli nasza zmiana weszła jako część większego wdrożenia i przywrócenie wersji cofnie również inne zmiany, które działają i nie powinny albo nie mogą zostać cofnięte? Powrót do poprzedniej wersji nie zawsze jest możliwy więc szukamy przyczyny błędu poprawiamy go i wdrażamy poprawkę. Całość zajmuje określony czas wstrzymując możliwość korzystania z systemu. Dlaczego tak się dzieje? Analizując standardowe podejście pisania kodu, można zauważyć jeden, powtarzalny model: Request\Response. Polega on na wywołaniu metody (Request) i czekaniu na odpowiedź (Response). Jak wszystko działa to program przechodzi do kolejnego wywołania. Jak jest sytuacja awaryjna program zgłasza wyjątek, który obsługujemy w taki czy inny sposób. Model ten przyjmujemy jako standard na wszystkich warstwach:
- w bazie danych
exec doSomething v1, v2, ...;
- w procesie aplikacji
someObject.DoSomething(v1, v2, …);
- w wywołaniu zdalnym
someProxy.DoSomething(v1, v2, …);
Dodatkowo wprowadzamy zależności. Jedna metoda woła inną metodę, a ta z kolejki może wołać jeszcze inną. Do tego dochodzą kwestię sprzętowe, sieć, uprawnienia itd. Jeśli chociaż jeden z tych złożonych elementów “zawiedzie” dostajemy “wyjątek”, który może zablokować cały system. Im bardziej złożony system w którym wprowadzamy zmiany tym większe prawdopodobieństwo, że taka sytuacja może wystąpić, dlatego robimy wszystko co możemy, aby zmniejszyć prawdopodobieństwo wystąpienia takiej sytuacji - testowanie. Niestety mimo wszelkich starań, stosując wszystkie dobre praktyki, nie jesteśmy w stanie przewidzieć wszystkiego (hmm…). U mnie świadomość takiej sytuacji wprowadza “lekki” dreszczyk emocji przed wdrożeniem oraz automatycznie “uziemia” na dłuższą chwilę po wdrożeniu, żeby ewentualnie móc zareagować, co jest sytuacją średnio komfortową. Dobra wiadomość jest taka, że jak się przeżyje taką awaryjną sytuację, daje to “mega” doświadczenie i zmienia podejście do projektowania rozwiązania oraz pisania kodu.
Przez długi czas myślałem, że tak po prostu musi być, że jest to jeden z elementów wytwarzania oprogramowania, aż pewnego razu przeglądając Internet natrafiłem na postać Udi Dahan. Zapoznając się z jego wizją realizacji złożonych systemów doznałem tego fajnego uczucia “To jest to czego szukałem. To są odpowiedzi na pytania, które nurtowały mnie od bardzo długiego czasu.” Dodatkowo okazało się, że jest on twórcą framework’a o nazwie NServiceBus, który w łatwy sposób pozwala sprawdzić teorię w praktyce.
Zanim przejdziemy do szczegółów w jaki sposób NServiceBus daje komfort przy wdrażaniu nowych wersji wrócimy jeszcze do modelu Request\Response:
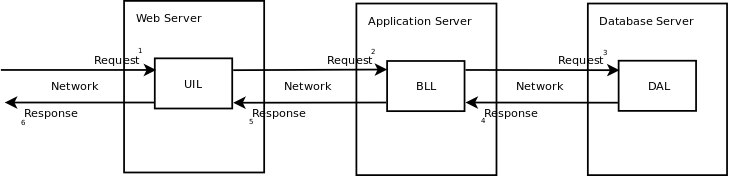
Diagram przedstawia synchroniczny/blokujący scenariusz wysłania na serwer webowy danych do przetworzenia:
- serwer przyjmuje
Requestz danymi - BLL wykonuje logikę, przetwarza reguły, itp.
- DAL zapisuje dane do bazy danych
- serwer zwraca
Responsedo klienta
Aby żądanie zostało przetworzone z sukcesem wszystkie elementy muszą działać. Całość trwa określony czas w którym to czasie klient wysyłający żądanie czeka na odpowiedź. Jeśli mamy błąd w BLL lub jeśli, DAL nie jest w stanie zapisać danych do bazy zgłaszany jest wyjątek, który trafia do klienta z mniej lub bardziej przyjaznym komunikatem, a do programistów zazwyczaj w postaci loga. To jest ten moment w którym cała maszyna szybkiego reagowania startuje.
Jak w takim scenariuszu można użyć framework’a NServiceBus ?
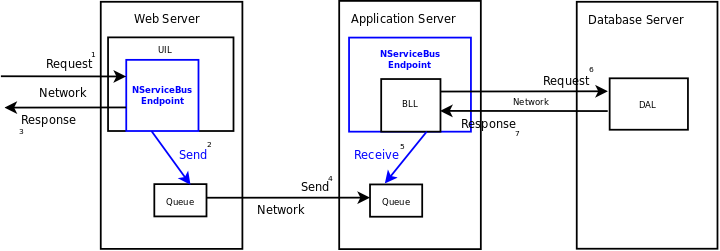
Diagram przedstawia ten sam scenariusz wysłania na serwer webowy danych do przetworzenia. Elementy zaznaczone na niebiesko oznaczają miejsce użycia NServiceBus'a:
- serwer przyjmuje Request z danymi
- tworzony jest
messagez danymi NServiceBuswysyła message do kolejki- serwer zwraca Response do klienta z informacją w stylu:
- “Dziękujemy, zgłoszenie zostało przyjęte do realizacji”
osobny proces na serwerze aplikacyjnym
- NServieBus pobiera message z kolejki
- BLL wykonuje logikę, przetwarza reguły, itp.
- DAL zapisuje dane do bazy danych
Pierwsza różnica w stosunku do modelu Reqest\Response jest taka, że żądanie przetwarzane jest asynchronicznie. Po wstawieniu message’a do kolejki klient dostaje odpowiedź “Dziękujemy, zgłoszenie zostało przyjęte do realizacji” co pozwala mu kontynuować pracę, ale nie oznacza, że żądanie zostało przetworzone. Taki sposób przetwarzania żądań najbardziej pasuje do scenariuszy, które z definicji są asynchroniczne.
Drugą różnicą w stosunku do modelu Reqest\Response jest sposób obsługi sytuacji awaryjnych. W takich sytuacjach NServiceBus pokazuje swoją moc (jedną z wielu :)). Jeśli coś pójdzie nie tak, nie tylko zaloguje taką informację, ale automatycznie ponowi próbę przetworzenia message’a. Jeśli problemem był timeout lub deadlock na bazie danych, jest duża szansa, że po ponowieniu próby problem ten nie wystąpi. W ten sposób z automatu odpadają nam wszystkie problemy z tymczasową niedostępnością zasobów! A co jeśli błąd jest w kodzie i będzie występował dopóki nie wdrożymy poprawki? NServiceBus posiada strategię ponawiania przetwarzania message’a (którą można konfigurować) i po określonej liczbie prób “poddaje się” i przenosi message do innej kolejki zwanej kolejką z błędami, po czym zaczyna przetwarzać kolejny message z kolejki docelowej, który być może przetworzy się prawidłowo. W tym czasie użytkownicy mogą korzystać z systemu! Ich zgłoszenia cały czas są przyjmowane natomiast nie są przetwarzane. Czekają sobie spokojnie na poprawkę. Taka sytuacja daje nam komfort i czas w procesie znalezienia oraz naprawienia kodu generującego problem co jest bardzo fajną cechą NServieBus’a. Po wdrożeniu nowej wersji, możemy przywrócić message’e z kolejki z błędami do kolejki docelowej i w ten sposób wszystkie dane przesłane przez użytkowników zostają przetworzone w prawidłowy sposób. Przykładowy scenariusz dokładnie opisany jest w artykule z dokumentacji https://docs.particular.net/tutorials/intro-to-nservicebus/].
Poniżej skrócony przykład w jaki sposób można zastosować tę technikę w scenariuszu zaproszenia gracza na mecz tenisa:
- wysłanie wiadomości do kolejki
private static async Task SendMessage(IEndpointInstance endpointInstance)
{
var message = new InviteForTennisMatch
{
Id = Guid.NewGuid(),
Player1 = Guid.NewGuid(),
Player2 = Guid.NewGuid()
};
await endpointInstance.Send(message);
}- przetwarzanie wiadomości
public class Handler : IHandleMessages<InviteForTennisMatch>
{
public Task Handle(
InviteForTennisMatch message,
IMessageHandlerContext context)
{
// BLL code
// DAL code
return Task.CompletedTask;
}
}Podsumowanie
NServiceBus jest krokiem naprzód w procesie wytwarzania oprogramowania. Umożliwia budowanie bardziej niezawodnych systemów. Daje programistom czas i spokój w momencie kiedy jest on najbardziej potrzebny, czyli w sytuacji gdy występują problemy w krytycznej części systemu. Użytkownikom umożliwia zaś kontynuowanie pracy, kiedy takie problemy występują. Oczywiście nie jest on lekiem na wszystkie bolączki. W niektórych sytuacjach nie ma on zastosowania, w innych wymaga przeprojektowania rozwiązania, a w jeszcze innych przeszkolenia i zmiany sposobu podejścia do używania systemów przez końcowych użytkowników. Gdy jednak uda się te wyzwania przezwyciężyć i gdy spotka nas krytyczna sytuacja, nie ma lepszego uczucia niż “no widzę, że lecą błędy, coś nie gra, poprawię to na spokojnie i przywrócę wiadomości z kolejki z błędami - nie blokuję użytkowników a ich dotychczasowe wysłane dane nie przepadły”
Podsumowując całą serię można rzec: od kodu maszynowego, przez techniki programowania, wzorce projektowe i architektury do messaging’u. Wszystko te klocki złożone razem dają niezłe efekty i dużo frajdy w procesie wytwarzania oprogramowania. Warto zawsze pamiętać aby ze zbioru wielu możliwych języków, framework’ów, bibliotek, architektur i innych czynników, dobierać te, które pozwolą nam na realizację oprogramowania zgodnego z oczekiwaniami klienta.
=