Wytwarzanie oprogramowania III - architektury systemów informatycznych
Posty z tej serii:
- Wytwarzanie oprogramowania I - paradygmaty programowania
- Wytwarzanie oprogramowania II - techniki programowania
- Wytwarzanie oprogramowania III - architektury systemów informatycznych
- Wytwarzanie oprogramowania IV - NServiceBus - framework, który zmienia zasady gry
Trzeci wpis z serii „Wytwarzanie oprogramowania” zawiera przegląd wybranych architektur do konstruowania biznesowych aplikacji oraz biznesowych systemów informatycznych.
Z poprzednich wpisów wiemy, jakich paradygmatów programowania oraz jakich technik programistycznych można używać w procesie wytwarzania oprogramowania. Kolejnym etapem jest połączenie tych elementów w całość i dostarczenie końcowemu użytkownikowi. W większości przypadków programista realizuje trzy rodzaje elementów składających się na całość funkcjonalności:
- interfejs użytkownika oraz zdarzenia generowane przez użytkownika
- logika aplikacji
- operacje na bazie danych
W takim modelu kod można podzielić na trzy podstawowe warstwy (layers):
- warstwa interfejsu użytkownika (UIL - User Interface Layer)
- warstwa logiki biznesowej (BLL - Business Logic Layer)
- warstwa dostępu do danych (DAL - Data Access Layer)
Kod napisany w każdej z tych warstw łączony jest w całość i…no właśnie, co dalej z tym kodem można zrobić ?
Ano trzeba to oprogramowanie wdrożyć na maszynę z którą użytkownicy będą się łączyć aby korzystać z funkcjonalności. Większość systemów biznesowych “wpada” w cykl, który składa się z kilku, kilkunastu kroków. Trzy podstawowe to:
- Wytwarzanie
- Utrzymanie
- Rozwój
Cykl taki ma wtedy postać: wytworzenie -> utrzymanie -> rozwój -> utrzymanie -> rozwój -> … Każdy z tych kroków jest bardzo ważny i każdy z nich posiada własną charakterystykę.
-
Wytwarzanie
W trakcie tego etapu programiści wytwarzają oprogramowanie zgodne z dostarczonymi wymaganiami. Żaden użytkownik jeszcze nie korzysta z tego oprogramowania, więc kod można konstruować właściwie w dowolny sposób sprawdzając jakie techniki najbardziej pasują do realizacji funkcjonalności.
-
Utrzymanie
Po wdrożeniu funkcjonalności zaczyna się faza utrzymania. Użytkownicy wykorzystują system, aby robić biznes. W tej fazie dostrajane są różne elementy a także wprowadzane drobne zmiany zgłaszane przez użytkowników. Programiści nie mogą już ot tak sobie wprowadzić zmiany, ponieważ intencją jest też to, aby “nie zepsuć” tego, co już działa. W tym momencie bardzo przydają się testy, zarówno jednostkowe, jak i integracyjne, które weryfikują, czy wprowadzone zmiany “nie psują” pozostałej części. Jest to też moment na prawdziwy test wcześniejszej konstrukcji kodu. Nawet jeśli autorzy zdecydowali, że pewne fragmenty kodu są na tyle małe, że nie wymagają testów, ale przewidzieli, że w przyszłości takie testy mogą być potrzebne i odpowiednio skonstruowali kod to w tej fazie takie testy w miarę łatwo powinno się dać dopisać.
-
Rozwój
Na tym etapie aplikacja lub system działa stabilnie długi czas. Użytkownicy wiedzą jakie są mocne a jakie słabe strony, pojawiają się pomysły na nowe funkcjonalności lub całkowitą zamianę tych działających. Etap ten jest niejako połączeniem etapów wytwarzania i utrzymania. Jeżeli zmiany dotyczą części systemu to po wdrożeniu pozostałe części nadal muszą działać. Nowo zdefiniowane funkcjonalności być może są na tyle duże, że obecne algorytmy i konstrukcja kodu już nie pasują do ich realizacji więc trzeba sięgnąć po inne rozwiązania. Na tym etapie może okazać się, że napisane testy również są do zmiany, ponieważ cała idea funkcjonowania zmienia się.
Póki co nie ma sposobów na dostarczanie w 100% bezbłędnych systemów (hmm…), więc zawsze trzeba mieć na uwadze to, że po wdrożeniu coś może nie zadziałać, mimo że całość zmian przeszła przez wszystkie fazy testów. Wtedy ważny staje się czas, w jakim jesteśmy w stanie dostarczyć użytkownikom nową poprawioną wersję. Taką sytuację można podzielić na dwa scenariusze:
- Niepoprawne działanie w niekrytycznej części systemu
- Niepoprawne działanie w krytycznej części systemu
W pierwszym przypadku w zasadzie nieważne jest, jak szybko pojawi się nowa wersja, ważne aby się pojawiła. W drugim natomiast ma to dość istotne znaczenie. Poniżej opisuję cztery podstawowe sposoby konstrukcji i dostarczania aplikacji z uwzględnieniem scenariusza nr 2.
Client only
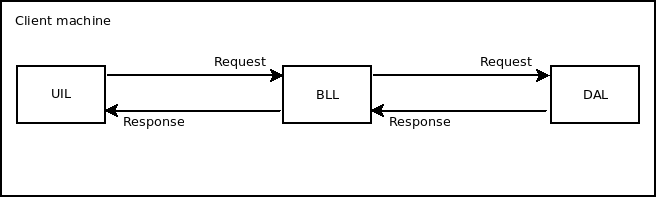
Całość wgrywana jest na maszynę użytkownika. Tak dostarczoną funkcjonalność można nazwać aplikacją, ponieważ nie łączy się ona przez sieć z żadnym innym elementem. Jeśli do działania wymagana jest sieć wtedy można nazwać ją systemem. Aplikacja może wykonywać operacje na bazie danych, wtedy baza ta również znajduje się na maszynie użytkownika. Przykładowe tego typu aplikacje to różnego rodzaju notatniki, kalkulatory, edytory tekstów, arkusze kalkulacyjne itp. Ponieważ trend jest taki aby wszystko było połączone z siecią, właściwie tego typu aplikacji już się nie pisze. Aby móc skorzystać z takiej aplikacji, użytkownik musi ją zainstalować na swojej maszynie. Proces dostarczania nowej wersji można zrealizować na co najmniej dwa sposoby:
- użytkownik pobiera nową wersję i instaluję ją na swojej maszynie
- aplikacja posiada moduł aktualizujący, który pobiera nową wersję z sieci i aktualizuje obecną, a po zakończeniu prosi użytkownika o ponowne uruchomienie aplikacji
Załóżmy, że z aplikacji korzysta 1000 osób:
- pojawia się nowa wersja ze zmianami w dowolnej warstwie (UIL\BLL\DAL)
- użytkownicy dostają powiadomienie i dokonują aktualizacji
- po uruchomieniu nowy wgrany kod przestaje działać
- użytkownicy nie mogą pracować
Po naprawieniu problematycznego kawałka kodu:
- trzeba ponownie powiadomić użytkowników o dostępność nowej poprawionej wersji
- użytkownicy dokonują aktualizacji
- po uruchomieniu nowy wgrany kod działa tak jak powinien
- użytkownicy wracają do pracy
W tym modelu użytkownik jest angażowany w proces aktualizacji. Musi otrzymać powiadomienie o konieczności aktualizacji oraz wykonać czynności aktualizacyjne. Całość zajmuje określony czas. Ważne jest też dopilnowanie aby wszystkie 1000 osób dokonało uaktualnienia.
Client + Database Server
W tej architekturze baza danych jak i DAL wdrażane są na osobną maszynę, często zwaną serwerem bazodanowym. Pozostałe elementy, jak poprzednio, wędrują na maszynę użytkownika. Kod na maszynie użytkownika łączy się poprzez sieć z kodem bazodanowym na serwerze bazodanowym, dlatego tak dostarczaną funkcjonalność można nazwać systemem.
Do takiego systemu zmiany wprowadzane są na dwa sposoby:
- jeśli zmiana dotyczy UIL lub BLL, to proces jest taki sam jak w poprzednim punkcie
- jeśli zmiana dotyczy bazy danych lub DAL, to zmianę tę wprowadza się w jednym miejscu - serwerze bazodanowym
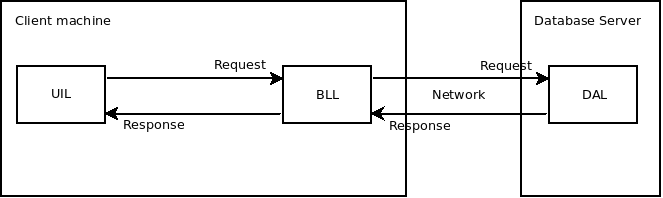
Rozpatrując ten sam przypadek powdrożeniowych wyzwań w krytycznej części systemu co poprzednio, jeśli zmiana dotyczy DAL to aktualizacja odbywa się w jednym miejscu i po jej dokonaniu 1000 użytkowników od razu może zauważyć efekt. Czas dostarczenia nowej wersji skraca się zauważalnie. Użytkownicy nie muszą pobierać nowej wersji, a czasami nawet czekać na powiadomienie o jej dostępności. Mogą wrócić do pracy. E-mail informujący o awarii zawsze warto wysłać, żeby użytkownicy wiedzieli z jakiego powodu nastąpiła przerwa w działaniu.
Client + Application Server + Database Server
Czas, jaki upływa pomiędzy wdrażaniem zmian po stronie bazy danych a wdrażaniem zmian po stronie klienta, może zachęcać do tego, aby pisać jak najwięcej kodu właśnie po stronie bazy danych. Nie tylko tego związanego z DAL, ale również z BLL. Jednak już przy średnio zaawansowanym systemie okazuje się, że większość elementów składających się na działanie systemu pisze się łatwiej, szybciej i bardziej dokładnie w językach niezależnych od bazy danych. W takiej architekturze BLL wdraża się na tzw. serwer aplikacyjny. Funkcjonalności DAL dalej wdrażane są na serwer bazodanowy, a funkcjonalności UIL jak poprzednio dostarczane są na maszynę kliencką. Taki system ma zatem trzy elementy wdrożeniowe:
- jeśli zmiana dotyczy UIL, to proces jest taki sam jak w poprzednich punktach
- jeśli zmiana dotyczy BLL, to zmianę wprowadza się w jednym miejscu - serwerze aplikacyjnym
- jeśli zmiana dotyczy DAL, to proces jest taki sam jak w poprzednim punkcie
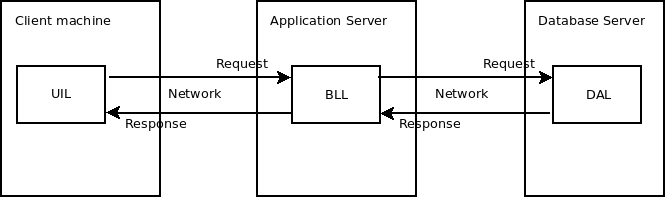
Teraz podobnie jak dla DAL, zmiany w BLL wdrażane są w jedno miejsce, co powoduje, że po dostarczeniu naprawionej funkcjonalności wszystkie osoby widzą zmianę od razu. Dodatkowo jeśli BLL realizowane jest w paradygmacie obiektowym, to w implementacji BLL można korzystać ze wszystkich jego dobrodziejstw. Jeśli większość zmian w systemie dotyczy BLL i DAL to większość nowych wdrożeń nie wymaga od użytkownika żadnej akcji, przez co czas wdrożenia poprawionej wersji u wszystkich 1000 osób znowu się skraca.
Client + Web Server + Application Server + Database Server
A czy można coś zrobić z funkcjonalnościami UIL? Wszystkie trzy pozostałe architektury w założeniu mają to, że jakaś część systemu jest instalowana na maszynie użytkownika. Są to tak zwane systemy “dekstopowe”. Jeśli wymagania biznesowe nie narzucają takiej architektury, to można również UIL przenieść i wdrażać w jedno centralne miejsce na tzw. serwer webowy. System taki dalej posiada trzy elementy wdrożeniowe:
- jeśli zmiana dotyczy UIL, to zmianę wprowadza się w jednym miejscu - serwerze webowym
- jeśli zmiana dotyczy BLL, to proces jest taki sam, jak w poprzednim punkcie
- jeśli zmiana dotyczy DAL, to proces jest taki sam, jak w poprzednich punktach
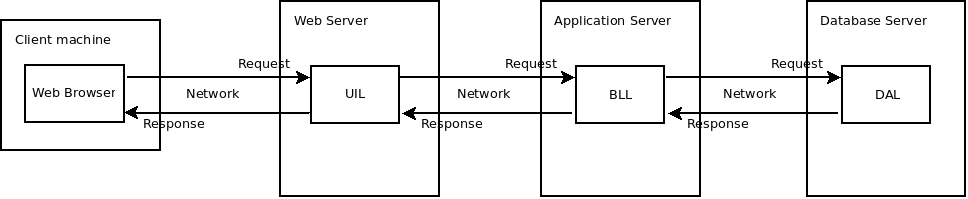
W tej architekturze wszystkie trzy elementy wdraża się w centralne miejsca przez co użytkownikom pozostaje tylko czekanie na dostarczenie nowej poprawionej wersji. Takie systemy nazywa się systemami “webowymi” i dostęp do nich uzyskuje się przez przeglądarkę internetową, która jest jedynym elementem, który użytkownik musi posiadać na swojej maszynie. W takiej architekturze czas wdrożenia nowej wersji ponownie się skraca, gdyż teraz niezależnie, gdzie są wprowadzane zmiany (UIL, BLL czy DAL) proces wdrażania jest taki sam, przez co użytkownicy nie biorą bezpośredniego udziału w procesie aktualizacji.
Podsumowanie
Sytuacja, w której po wdrożeniu nowej wersji systemu użytkownicy nie mogą kontynuować swojej pracy jest bardzo niekomfortowa zarówno dla samych użytkowników jak i dla programistów. Oczywiście zawsze warto, a nawet trzeba, zrobić wszystko, aby taka sytuacja nie miała miejsca, ale jak wiadomo z doświadczenia zdarzają się mniejsze lub większe chochliki, które potrafią bardziej lub mniej namieszać, zwłaszcza, jeśli systemy rozwijane są przez bardzo dużą liczbę osób. Post ten koncentruje się na czasie wdrożenia nowej wersji, natomiast przy wyborze architektury mogą mieć znaczenie również inne elementy, np.
- Czy dostęp do danych jest współbieżny?
- Jakie zasoby fizyczne maszyn są potrzebne aby zrealizować system?
- Czy wystarczy jeden serwer czy potrzebna jest farma serwerów?
- Jak szybko użytkownicy będą mogli zacząć korzystać z systemu, czy będą musieli instalować dodatkowe komponenty?
- Co z bezpieczeństwem danych i stworzonych algorytmów?
- …
Patrząc jeszcze raz na “czarny” scenariusz:
- pojawia się nowa wersja ze zmianami w dowolnej warstwie (UIL\BLL\DAL)
- po uruchomieniu nowy kod przestaje działać
- użytkownicy nie mogą pracować
Po zdiagnozowaniu, naprawieniu problematycznego kawałka kodu i ponownym wdrożeniu:
- nowy kod działa zgodnie z oczekiwaniami
- użytkownicy wracają do pracy
Można zauważyć, że post ten dotyczy czasu związanego z ponownym wdrożeniem. Co natomiast z czasem związanym ze zdiagnozowaniem i naprawianiem problematycznego kawałka kodu? O tym będzie następny post z tej serii.
=