Monitoring z Particular Service Platform
Posty z tej serii:
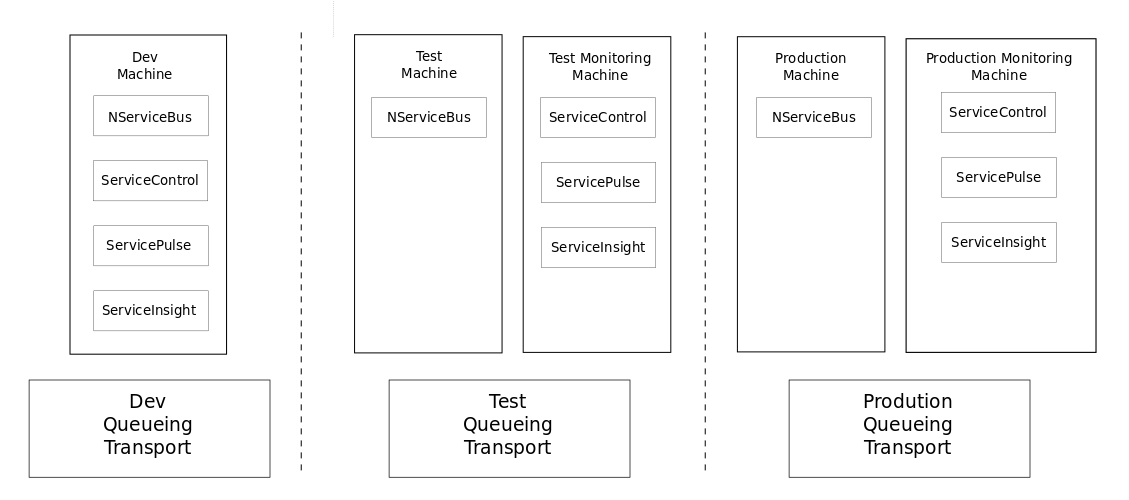
Z poprzedniego artykułu wiemy, jak instalować i konfigurować poszczególne komponenty platformy Particular. Wiemy też, w jaki sposób poszczególne komponenty wspomagają nas na etapie realizacji funkcjonalności. W tym artykule przejdziemy przez elementy, które przydają się po fazie Deploy. Kontekst treści dotyczy wdrożeń produkcyjnych, natomiast opisane techniki z powodzeniem można stosować na każdym środowisku wdrożeniowym. Przykładowa architektura instalacji poszczególnych komponentów może wyglądać tak:
Pierwszą przydatną powdrożeniową funkcjonalnością jest…przywracanie wiadomości z kolejki błędów. O ile w fazie rozwoju możemy potraktować tę funkcjonalność jako “nice to have”, to w fazie monitoringu wdrożonych komponentów jest to “must to have”. Na tym etapie chcemy maksymalnie skupić się na znalezieniu problemu oraz jego poprawie. Samo przywracanie wiadomości do ponownego przetworzenia powinno być “bezbolesne”. Nie chcemy sami ręcznie szukać, do jakiej kolejki źródłowej powinny być przywrócone wiadomości, zwłaszcza w sytuacji, gdy funkcjonalności działą już od jakiegoś czasu, a my zajmujemy się już innymi tematami. Tutaj z pomocą przychodzi nam ServicePulse.
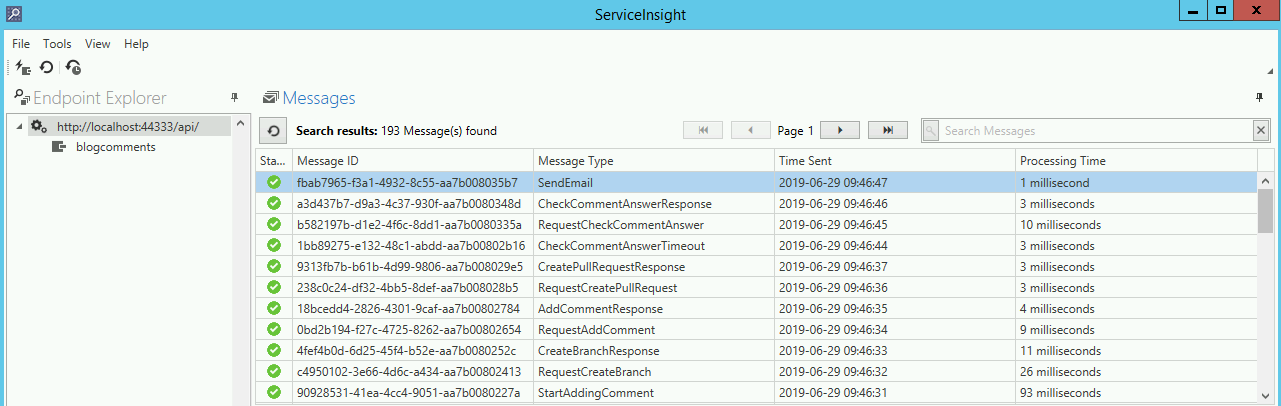
Drugą funkcjonalnością jest przeglądanie i analiza przesłanych wiadomości w celu znalezienia przyczyny zgłaszanych nieprawidłowości w działaniu systemu. Trzecią funkcjonalnością jest analiza powiązań pomiędzy poszczególnymi wiadomościami. Chcemy zapoznać się lub przypomnieć sobie, jakie jest flow systemu, np. w celu znalezienia odpowiedniego miejsca do zakodowania nowej funkcjonalności. W tym przypadku pomocny będzie ServiceInsight.
Wszystkich trzech technik używa się tak samo niezależnie od środowiska wdrożeniowego. Szczegóły można znaleźć w poprzednim artykule.
Kolejne przydatne funkcjonalności to elementy monitoringu wdrożonych komponentów. Zobaczmy, w jaki sposób można użyć Platformy Particular do:
- monitorowania, czy Endpointy NServiceBusa są uruchomione - Heartbeats
- monitorowania metryk wydajności uruchomionych Endpointów NServiceBusa - Monitoring
ServiceControl
Tym razem zacznijmy od ServiceControla. Sposób instalacji jest dokładnie taki sam, niezależnie od maszyny instalacyjnej. Istotną różnicą pomiędzy środowiskiem developerskim a produkcyjnym jest ilość wiadomości do przetworzenia. Programując nowe funkcjonalności, to my i tylko my generujemy wiadomości. Na środowisku produkcyjnym wiadomości generowane są przez użytkowników. Ilość wygenerowanych wiadomości zależy od funkcjonalności oraz ilości osób korzystających z systemu. Zadaniem ServiceControla jest jak najszybsze przetworzenie danych i udostępnienie ich pozostałym komponentom Platformy. W związku z tym trzeba zaplanować ilość zasobów, jakie będą potrzebne, aby ServiceControl działa optymalnie:
- przepustowość - ilość wiadomości, jakie ServiceControl będzie miał do przetworzenia
- sprzęt - ilość procesorów, pamięć RAM, pojemność dysku twardego, …
- bezpieczeństwo - kto będzie miał dostęp do udostępnianych danych
Więcej informacji, na co szczególnie należy zwrócić uwagę, można znaleźć w dokumentacji.
Najlepiej, aby ServiceControl był instalowany na innej maszynie niż Endpointy NServiceBusa. W ten sposób nie będzie on wpływał na ich wydajność. Taka architektura ułatwi aktualizacje do nowszych wersji oraz przeprowadzanie prac konserwacyjnych. W razie restartu całego systemu operacyjnego nie będzie to miało wpływu na przetwarzanie danych biznesowych.
Po pomyślnej instalacji konfigurujemy instancję ServiceControla w taki sam sposób, jaki został opisany w poprzednim artykule, wskazując produkcyjne nazwy kolejek error oraz audit. Po skonfigurowaniu instancji, ServiceControl jest gotowy do obsługi Hearbeatów.
Do monitorowania metryk wydajności potrzebna jest osobna instancja monitoringu. Przejdźmy przez kolejne kroki konfiguracji takiej instancji dla ServiceControla w wersji 3.8.2
Utworzenie i konfiguracja instancji monitoringu


Po kliknięciu na przycisk New, wybieramy opcję Add monitoring instance…, a następnie konfigurujemy parametry instancji.
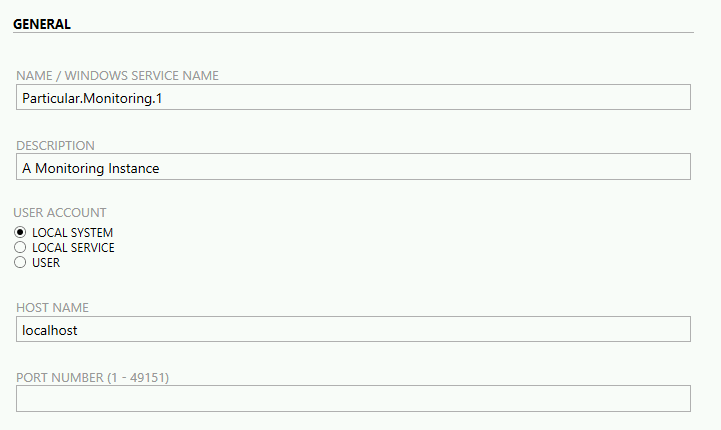
- NAME / WINDOWS SERVICE NAME - nazwa instancji, z którą powiązane będą pozostałe elementy:
- nazwy kolejek - ServiceControl tworzy oddzielną kolejkę dla monitoringu
- nazwa katalogu z utworzoną instancją
- nazwa usługi windows - instancja monitoringu jest hostowana jako usługa windows
- itp.
- DESCRIPTION - opis instancji - używany jako opis usługi windows
- USER ACCOUNT - konto użytkownika, na którym będzie uruchomiona usługa windows. Ważne, aby konto miało odpowiednie uprawnienia, np.
- możliwość tworzenia i uruchamiania usług windows
- tworzenia kolejek MSMQ - jeśli taki transport został wybrany
- itp.
- HOST NAME - definiuje poziom dostępu do danych udostępnianych przez ServiceControla:
- pozostawienie wartości localhost - dostęp do HTTP API tylko z maszyny instalacyjnej - większe bezpieczeństwo
- wpisanie pełnej nazwy maszyny - dostęp do HTTP API również z poza maszyny instalacyjnej- mniejsze bezpieczeństwo
- PORT NUMBER (1 - 49151) - numer portu, pod którym będzie dostępna instancja monitoringu
- DESTINATION PATH - miejsce instalacji instancji
- LOG PATH - logi generowane przez instancję monitoringu
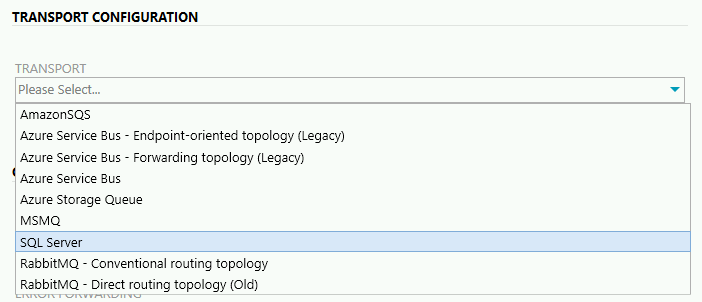
TRANSPORT - Wybieramy transport, którego używamy do wytwarzania funkcjonalności. Typ transportu musi być taki sam, jaki jest wykorzystywany w Endpointach NServiceBusa.

ERROR QUEUE NAME - nazwa kolejki na błędne wiadomości
Po zapisaniu konfiguracji, ServiceControl Management utworzy nową instancję monitoringu oraz uruchomi usługę windows. Przykładowa konfiguracja z użyciem SQL Server Transport może wyglądać tak:
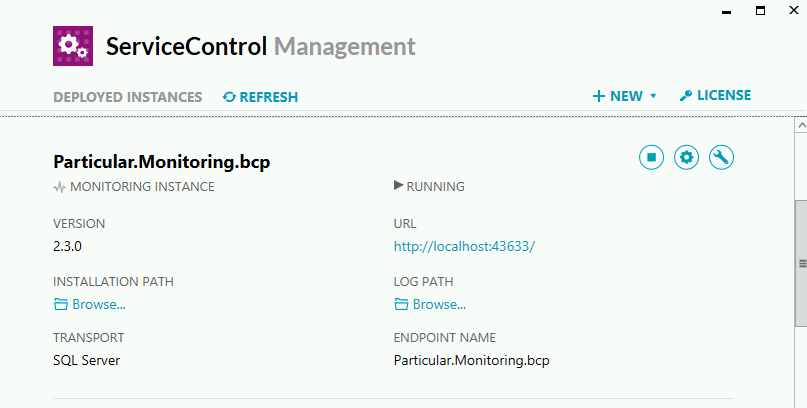
W tym momencie instancja jest gotowa do wykorzystania przez kolejne komponenty Platformy.
NServiceBus
Aby uruchomić funkcjonalność Heartbeats, instalujemy w projekcie paczkę nugetową NServiceBus.Heartbeat, a następnie konfigurujemy Endpointa:
endpointConfiguration.SendHeartbeatTo(
serviceControlQueue: "Particular.ServiceControl.bcp");W ten sposób instruujemy NServiceBusa, aby w odstępach czasowych zgłaszał informację, że jest uruchomiony, wysyłając wiadomość Heartbeat do odpowiedniej kolejki ServiceControla. W przykładzie jest to kolejka o nazwie Particular.ServiceControl.bcp.
Aby uruchomić funkcjonalność Monitoringu, instalujemy w projekcie paczki nugetowe:
Następnie konfigurujemy Endpointa:
var metrics = endpointConfiguration.EnableMetrics();
metrics.SendMetricDataToServiceControl(
serviceControlMetricsAddress: "Particular.Monitoring.bcp",
interval: TimeSpan.FromSeconds(1));W ten sposób instruujemy NServiceBusa, aby w odstępach czasowych zgłaszał metryki wydajności dotyczące uruchomionego Endpointa, wysyłając wiadomości do odpowiedniej kolejki monitoringu ServiceControla. W przykładzie jest to kolejka o nazwie Particular.Monitoring.bcp.
W nagłówkach każdej wysłanej wiadomości znajduje się informacja jednoznacznie identyfikująca Endpoint, z którego dana wiadomość została wysłana. Dzięki temu ServicePulse oraz ServiceInsight mogą wyświetlać nazwy Endpointów powiązanych z wiadomościami. W domyślnej implementacji NServiceBusa jedną ze składowych identyfikatora jest ścieżka do plików wykonywalnych. Jeśli tę samą instancję Endpointa z każdym nowym wdrożeniem uruchamiamy z innej ścieżki, to ServicePulse oraz ServiceInsight za każdym razem będą traktować tę instancje jako nową, co ma wpływ na poprawne wyświetlanie nazwy Endpointa. Aby tego uniknąć, możemy zmienić domyślną implementację, konfigurując tzw. Host Identifier.
endpointConfiguration.UniquelyIdentifyRunningInstance()
.UsingNames(
instanceName: "blogcomments",
hostName: Environment.MachineName);W ten sposób niezależnie od tego, czy nową wersję instancji Endpointa wdrożymy w tej samej lokalizacji, czy w innej, ServicePulse oraz ServiceInsight zawsze będą wyświetlać jedną i tę samą nazwę. W przykładzie jest nazwa blogcomments.
ServicePulse
Mając skonfigurowaną produkcyjną instancję ServiceControla, a także produkcyjną instancję NServiceBusa, możemy podłączyć produkcyjnego ServicePulsa, aby monitorować uruchomione funkcjonalności. Oczywiście musimy mieć zainstalowaną produkcyjną wersję ServicePulsa. Sposób instalacji jest dokładnie taki sam jak opisany w poprzednim artykule. Różnicą jest to, że przy instalacji podajemy URLe do produkcyjnej instancji ServiceControla oraz do produkcyjnej instancji monitoringu ServiceControla. Sam ServicePulse nie potrzebuje aż tak mocnych zasobów, jak ServiceControl, także może być instalowany na tej samej maszynie co Endpointy NServiceBusa, tej samej maszynie co ServiceControl lub osobnej dedykowanej maszynie.
Heartbeats
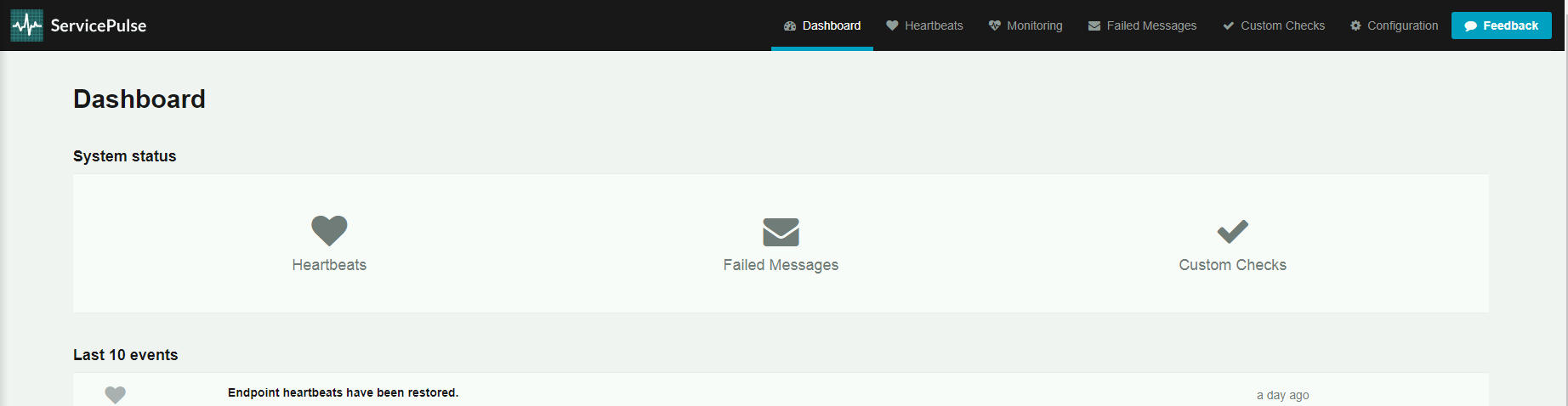
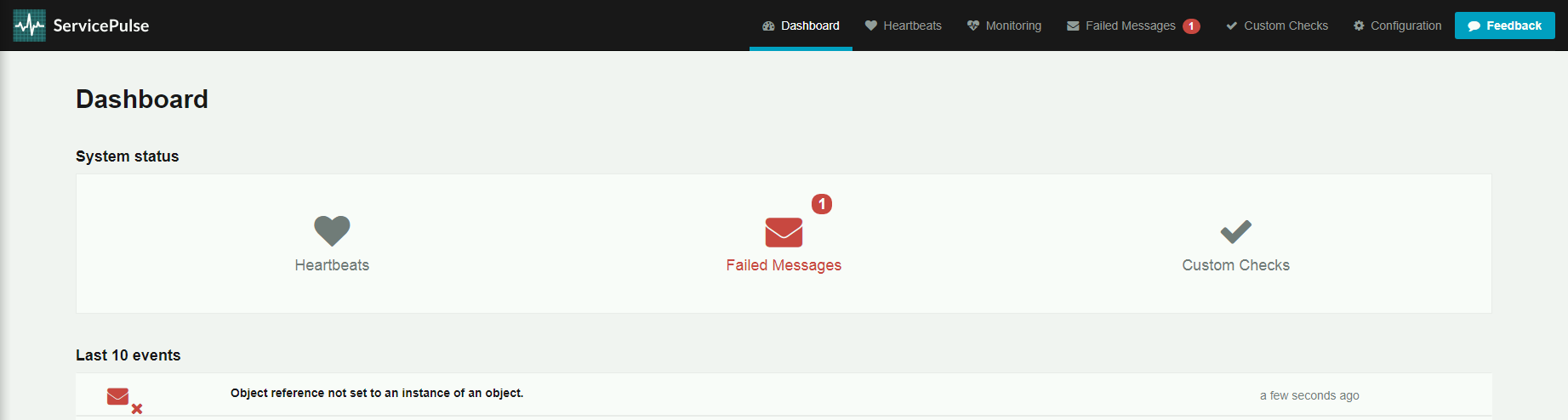
Jeśli Endpointy NServiceBusa wysyłają Heartbeaty, to zakładka Dashboard nie pokazuje żadnych błędów. Taki widok oznacza, że Endpointy są uruchomione i gotowe do przetwarzania wiadomości.

Po kliknięciu w zakładkę Hearbeats, widzimy listę aktywnych Endpointów.
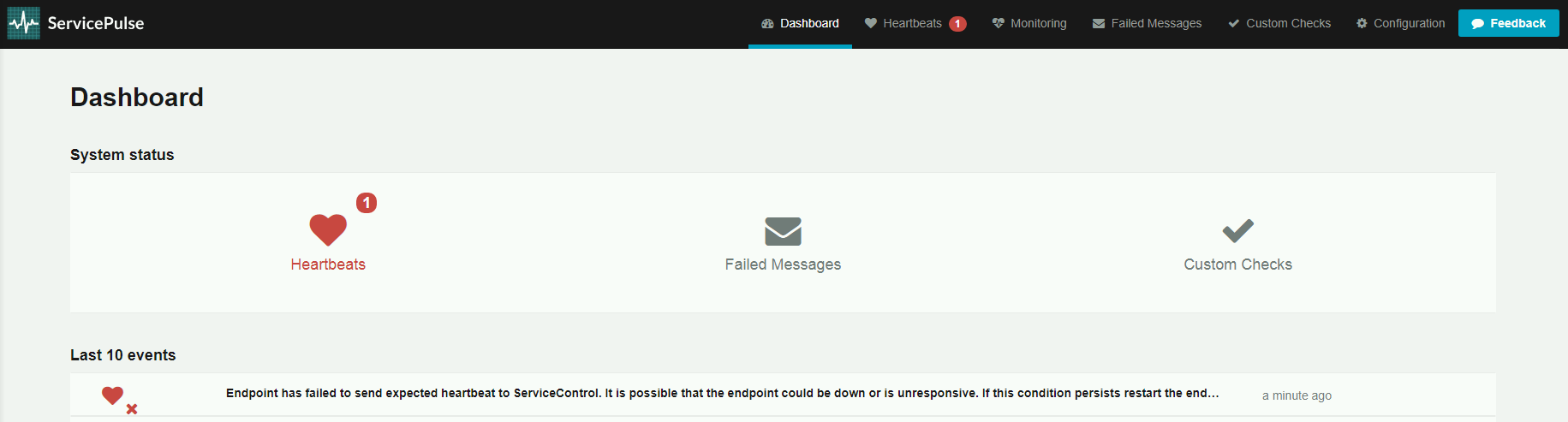
A tak wygląda widok ServiePulsa, jeśli któryś z Endpointów przestaje odpowiadać. Główne okno informuje nas o problemie.

Po kliknięciu w zakładkę Hearbeats, widzimy listę Endpointów nieaktywnych.
W takim przypadku jest to sygnał, że coś niedobrego dzieje się z Endpointami, a co za tym idzie, nie są przetwarzane wiadomości. W większości przypadków przyczyną są problemy z infrastrukturą lub błędną konfiguracją Endpointów. Informacji szukamy w logach Endpointów generowanych przez NServiceBusa. Po naprawieniu problemu i uruchomieniu Endpointów widok Dashboardu ServicePulsa wraca do poprawnego stanu.
Monitoring

Mając skonfigurowany monitoring, możemy obserwować metryki wydajności uruchomionych Endpointów. Klikając w zakładkę Monitoring, widzimy listę Endpointów wraz z informacjami:
- QUEUE LENGTH - liczba wiadomości oczekujących na przetworzenie
- THROUGHPUT - liczba poprawnie przetworzonych wiadomości - na sekundę
- SCHEDULED RETRY RATE - liczba wiadomości, w których nastąpiło ponowienie przetworzenie - na sekundę
- PROCESSING TIME - aktualny czas przetworzenia wiadomości
- CRITICAL TIME - czas jaki upłynął od momentu, kiedy wiadomość trafiła do kolejki, a jej poprawnym przetworzeniem
Metryki możemy obserwować z różnych okresów czasowych - od 1 minuty do 1 godziny. W powyższym przykładzie widzimy, że Endpoint blogcomments ma do przetworzenia jeszcze 939 wiadomości. W ostatniej sekundzie przetworzył 107 wiadomości. Żadna wiadomość nie została skierowana do ponownego przetworzenia. Czas przetwarzania wiadomości to 29 milisekund. Czas od momentu, kiedy wiadomość trafiła do kolejki, a jej poprawnym przetworzeniem to 13 sekund.
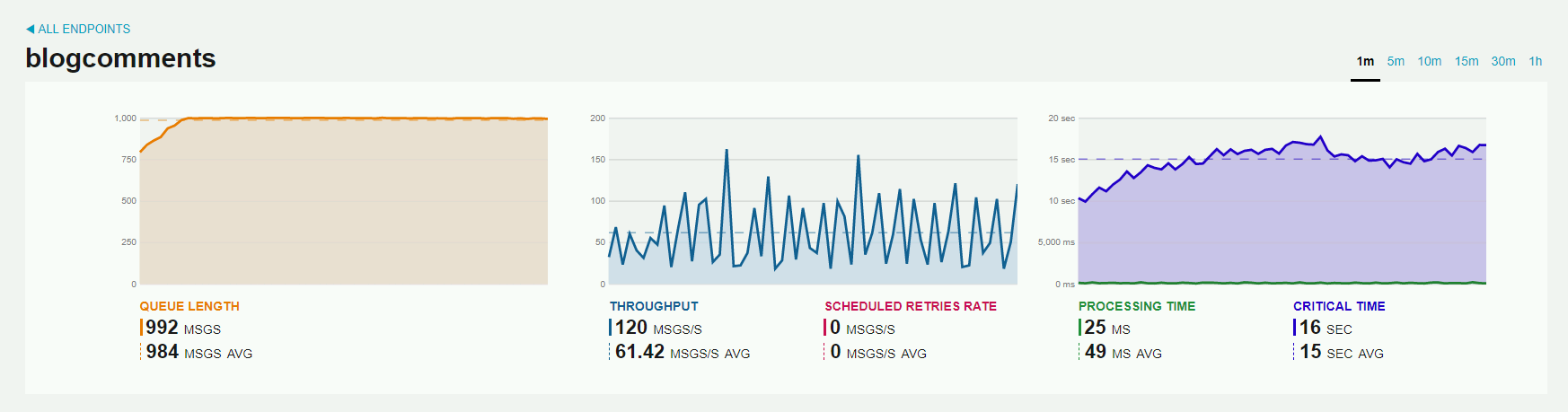
Po kliknięciu na konkretny Endpoint mamy widok z dodatkowymi metrykami pokazującymi średnie czasy z wybranej jednostki czasowej. W przykładzie są to metryki z ostatniej minuty, gdzie średnio w kolejce znajdowało się 984 wiadomości. Średnia ilość poprawnie przetworzonych wiadomości na sekundę to 61.42. Średni czas przetwarzania wiadomości to 49 milisekund. Średni czas, jaki upłynął od momentu, kiedy wiadomość trafiła do kolejki, a jej poprawnym przetworzeniem to 15 sekund.
Dzięki metrykom możemy obserwować zachowanie systemu oraz planować prace optymalizacyjne. Dla przykładu, jeśli wraz ze wzrostem ilości przetwarzanych danych widzimy, że CRITICAL TIME rośnie i zbliża się do nieakceptowanych wartości, to wiemy, że jest to czas na zdefiniowanie zadań optymalizacyjnych.
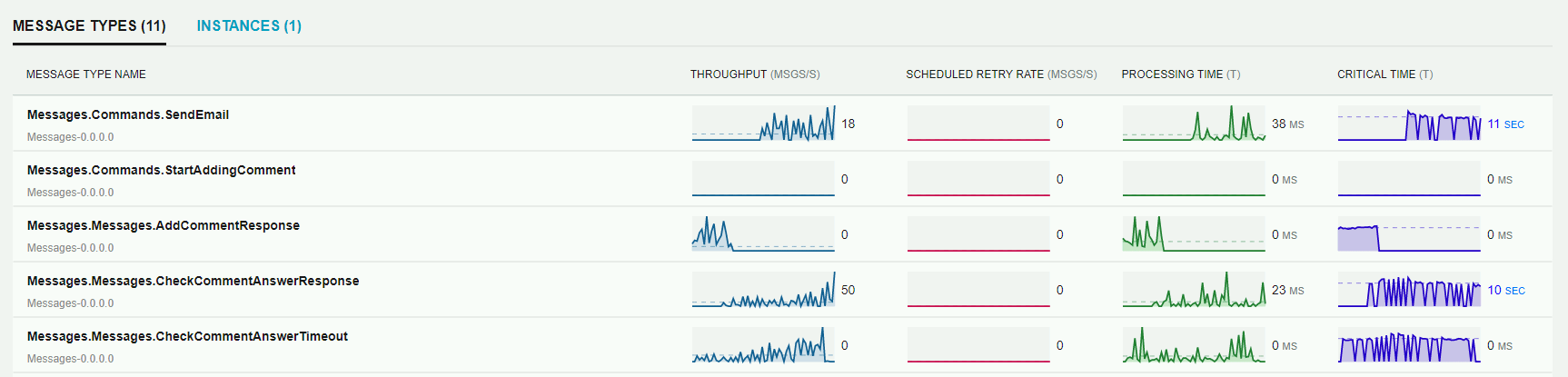
Widok szczegółowy Endpointa pokazuje również metryki dotyczące konkretnego typu wiadomości. Dzięki temu mamy możliwość podjęcia odpowiednich decyzji przy pracach optymalizacyjnych np. przeniesienie przetwarzania danego typu wiadomości na osobny Endpoint. Jeśli logiczny Endpoint wdrażamy na dwa osobne fizyczne środowiska, to klikając w zakładkę Instances, możemy zobaczyć metryki przetwarzania na konkretnym środowisku.

Widok monitoringu pokazuje również informacje o Endpointach, które przestały wysyłać Heartbeaty.

Dzięki metryce SCHEDULED RETRY RATE możemy obserwować sytuację, w której następuje ponawianie przetwarzania wiadomości. W takim przypadku, przy którymś z ponowień, wiadomość może wpaść do kolejki błędów lub zostać przetworzona z sukcesem. Jeśli wiadomość wpada do kolejki błędów, to z poprzedniego artykułu wiemy, co możemy z taką wiadomością zrobić. Jeśli wiadomości nie ma w kolejce błędów, a metryka pokazuje ponawianie, oznacza to, że któraś część systemu zachowuje się niestabilnie.
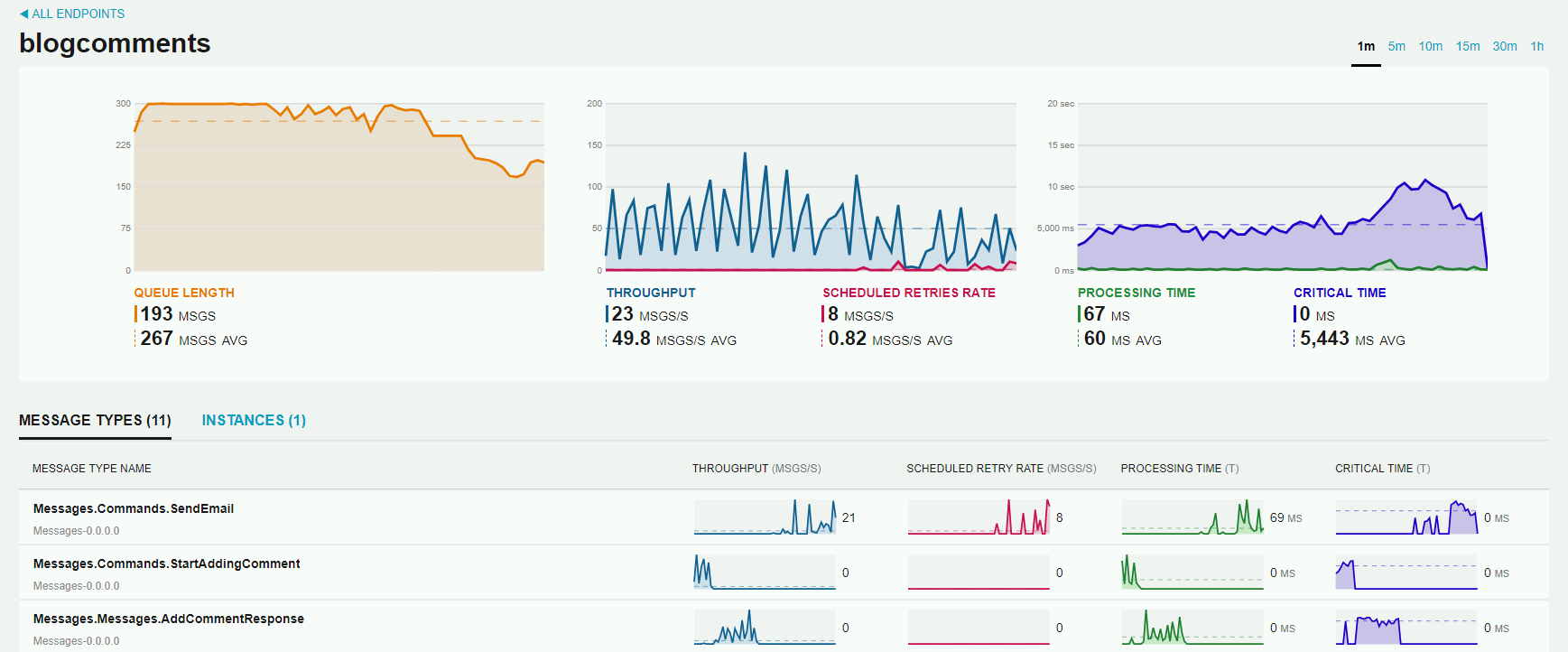
Przechodząc do szczegółowego widoku Endpointa, widzimy, dla których typów wiadomości następuje ponowne przetwarzanie. W przykładzie jest to wiadomość typu SendEmail. Może to oznaczać, że maile są wysyłane, ale np. przy drugiej, piątej, dziesiątej próbie. W logach Endpointa możemy sprawdzić, co powoduje takie zachowanie i podjąć odpowiednie kroki. Przykładowo, mogłoby się okazać, że serwer mailowy zwraca timeouty.
Custom Checks
W zakładce Dashboard ServicePulsa widzimy trzecią opcję o nazwie Custom Checks. Funkcjonalność tę można wykorzystać do monitorowania dowolnego zasobu. Pozwala ona na wpięcie napisanego przez nas kodu, który będzie cyklicznie uruchamiany. W kodzie możemy zwracać odpowiedni status (Pass lub Failed), który będzie wysyłany do ServiceControla. W przypadku statusu Failed, ServicePulse wyświetli informację, w taki sam sposób jak przy Hearbeats oraz Failed Messages.
Osobiście nie miałem jeszcze okazji do skorzystania z tej funkcjonalności, stąd tylko krótki opis idei działania. Więcej informacji można znaleźć na stronie dokumentacji.
Podsumowanie
W tej mini serii widzieliśmy, w jaki sposób Platforma Particular umożliwia wytwarzanie oprogramowania w oparciu o ideę Messagingu i Queueingu. Poszczególne komponenty platformy wspomagają nas na każdym etapie realizacji. Przy wdrożeniach, zwłaszcza nowych funkcjonalności, zawsze pojawia się ten dreszczyk emocji i pytanie - “Czy wszystkie elementy połączone razem zadziałają, tak jak powinny?”. Po chwili, gdy w ServicePulsie zaczynają pojawiać się pierwsze Heartbeaty, wykresy zaczynają się rysować, a w ServiceInsighcie widać przetworzone dane, następuje taka mini (choć czasami maxi :)) radość i odpowiedź “Wygląda na to, że działa!”. Dopełnieniem całości jest to, gdy widzimy błędy w zakładce “Failed Messages”. Namierzamy wtedy problem, sprawdzając StackTrace oraz połączone z nim dane. Wdrażamy poprawkę i przywracamy wiadomości do ponownego przetworzenia, które kończy się sukcesem. W takich sytuacjach świat staję się piękniejszy :). Po przejściu takiego cyklu widać jak Messaging i Queueing przesuwa nas do przodu w kierunku budowania bardziej niezawodnych systemów. Dzięki Particular Service Platform mamy możliwość realizacji takich systemów. Cała idea mocno wciąga i jak już raz się jej skosztuje, to nie ma powrotu ;)
=