Develop and Test z Particular Service Platform
Posty z tej serii:
W poprzednich artykułach pisałem o tym, w jaki sposób można wykorzystać framework NServiceBus w procesie wytwarzania oprogramowania. Framework ten jest częścią większej platformy zwanej Particular Service Platform. W tym artykule zobaczymy, jak pozostałe komponenty wchodzące w skład platformy pomagają na etapie Develop oraz Test, w kontekście trzech funkcjonalności:
- przywracania wiadomości z kolejki błędów do ponownego przetworzenia
- przeglądania i analizy historii przesłanych wiadomości
- analizy powiązań pomiędzy poszczególnymi wiadomościami
Funkcjonalności te przydają się również po fazie Deploy. Platforma Particular daje też możliwości monitoringu, co jest bardzo pomocne przy obserwowaniu produkcyjnie wdrożonych Endpointów NServiceBusa. Tym tematem zajmiemy się w kolejnym artykule.
Zanim przejdziemy do szczegółów, zobaczmy, z jakich elementów składa się Platforma Particular:
- NServiceBus - Komponent, od którego wszystko się zaczęło. Umożliwia realizację funkcjonalności w architekturze messagingu i queueingu.
- ServiceControl - Komponent zbierający informacje dostarczane przez NServiceBusa.
- ServicePulse - Komponent umożliwiający monitoring Endpointów NServiceBusa, a także obsługę messagey znajdujących się w kolejce z błędami.
- ServiceInsight - Komponent pozwalający na przeglądanie, analizowanie oraz wizualizację historii przesłanych messagey.
Więcej szczegółów o każdym z komponentów można znaleźć w dokumentacji technicznej platformy oraz na głównej stronie producenta.
NServiceBus
Aby móc skorzystać z funkcjonalności wymienionych we wstępie, trzeba skomunikować ze sobą poszczególne komponenty platformy. W przypadku NServiceBusa ustawiamy dwie właściwości, konfigurując Endpointa:
var endpointConfiguration = new EndpointConfiguration("blogcomments");
endpointConfiguration.SendFailedMessagesTo("error");
endpointConfiguration.AuditProcessedMessagesTo("audit");W momencie kiedy NServiceBus nie będzie w stanie przetworzyć wiadomości, wyśle ją do kolejki o nazwie error. Kopię wszystkich wiadomości będzie przesyłał do kolejki o nazwie audit. Każdy Endpoint składający się na całość rozwiązania musi mieć skonfigurowaną tę samą kolejkę audytową oraz kolejkę na błędy.
ServiceControl
Aby móc skorzystać z funkcjonalności ServiceControla, w pierwszej kolejności trzeba go zainstalować. Następnie trzeba utworzyć i skonfigurować jego instancję. W trakcie konfigurowania instancji podajemy nazwy kolejek, z których ServiceControl będzie pobierał nieprzetworzone wiadomości oraz kopie wiadomości wysyłanych przez NServiceBusa. W naszym przykładzie są to kolejki o nazwach error oraz audit. Po pobraniu wiadomości z kolejek, ServiceControl wstawia je do swojej wewnętrznej bazy danych - RavenDB w wersji embedded. Dostęp do danych udostępnia poprzez HTTP API.
Instalacja
Instalację można przeprowadzić co najmniej na trzy sposoby:
- instalując całą Particular Platform, korzystając z dostarczanego instalatora
- instalując samego ServiceControla, korzystając z dostarczanego instalatora
- instalując samego ServiceControla, w trybie Silently, korzystając z dostarczanego instalatora
Pliki instalacyjne dla wszystkich komponentów można znaleźć na stronie producenta. Opis instalacji w trybie Silently można znaleźć w dokumentacji, wpisując w wyszukiwarkę słowo kluczowe Silently.
Osobiście zawsze korzystam z opcji nr 2, zarówno przy świeżej instalacji jaki i aktualizacjach do nowszych wersji. Całość sprowadza się do pobrania pliku instalacyjnego, uruchomienia instalatora, a następnie przechodzenia przez kolejne okna instalacji poprzez kliknięcie opcji next. Zawsze też zostawiam domyślne wartości proponowane przez instalator.
Utworzenie i konfiguracja instancji
Po pomyślnej instalacji mamy dostęp do narzędzia o nazwie ServiceControl Management, które umożliwia tworzenie i konfigurowanie instancji.

Przejdźmy przez kolejne kroki konfiguracji dla ServiceControla w wersji 3.8.2

Po kliknięciu przycisku New mamy do wyboru dwie opcje
- Add ServiceControl Instance
- Add Monitoring Instance
Wybieramy opcję nr 1. Opcją nr 2 zajmiemy się w kolejnym artykule dotyczącym możliwości wykorzystania Particular Platform do monitorowania wdrożonych funkcjonalności.
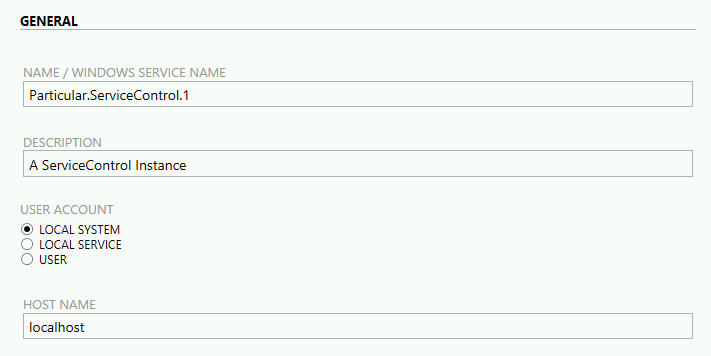
W nowym oknie konfigurujemy parametry instancji.
- NAME/WINDOWS SERVICE NAME - nazwa instancji, z którą powiązane będą pozostałe elementy:
- nazwy kolejek - ServiceControl do swojego działania używa kolejek
- nazwa katalogu z utworzoną instancją
- nazwa usługi windows - ServiceControl jest hostowany jako usługa windows
- itp.
- DESCRIPTION - opis instancji - używany jako opis usługi windows
- USER ACCOUNT - konto użytkownika, na którym będzie uruchomiona usługa windows. Ważne, aby konto miało odpowiednie uprawnienia, np.
- możliwość tworzenia i uruchamiania usług windows
- tworzenia kolejek MSMQ - jeśli taki transport został wybrany
- itp.
- HOST NAME - definiuje poziom dostępu do danych udostępnianych przez ServiceControla:
- pozostawienie wartości localhost - dostęp do HTTP API tylko z maszyny instalacyjnej - większe bezpieczeństwo
- wpisanie pełnej nazwy maszyny - dostęp do HTTP API również z poza maszyny instalacyjnej- mniejsze bezpieczeństwo

- PORT NUMBER (1 - 49151) - numer portu, pod którym będzie dostępna instancja
- MAINTENANCE PORT NUMBER (1 - 49151) - numer portu, po którym będzie dostępna instancja w trybie maintenance
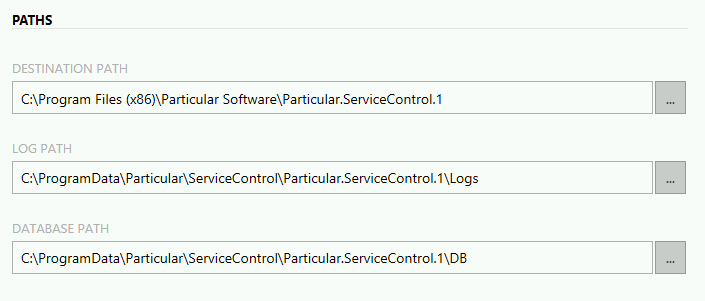
- DESTINATION PATH - miejsce instalacji instancji
- LOG PATH - logi generowane przez instancję ServiceControl
- DATABASE PATH - logi generowane przez bazę RavenDB
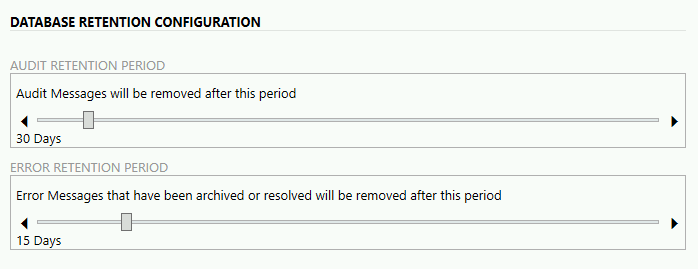
- AUDIT RETENTION PERIOD - definiujemy, po jakim czasie zaudytowane wiadomości będą usuwane z bazy danych
- ERROR RETENTION PERIOD - definiujemy, po jakim czasie zarchiwizowane wiadomości będą usuwane z bazy danych
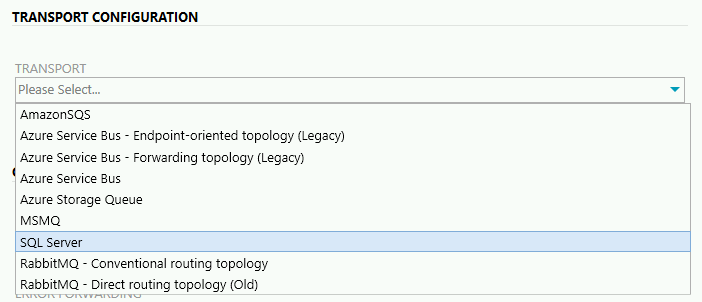
TRANSPORT - Wybieramy transport, którego używamy do wytwarzania funkcjonalności. Typ transportu musi być taki sam, jaki jest wykorzystywany w Endpointach NServiceBusa.
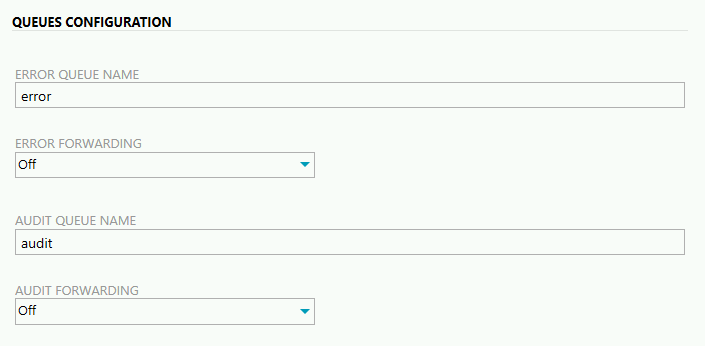
- ERROR QUEUE NAME - nazwa kolejki, z której ServiceControl będzie pobierał nieprzetworzone wiadomości. W naszym przykładzie jest to kolejka o nazwie error.
- ERROR FORWARDING - decydujemy, czy nieprzetworzone wiadomości mają być skopiowane do jeszcze jakiejś innej kolejki. Po wybraniu opcji ON pojawia się pole do wpisania nazwy takiej kolejki. Funkcjonalność ta może być pomocna, jeśli chcemy zrobić coś niestandardowego z takimi wiadomościami.
- AUDIT QUEUE NAME - nazwa kolejki z której ServiceControl będzie pobierał zaudytowane wiadomości. W naszym przykładzie jest to kolejka o nazwie audit.
- AUDIT FORWARDING - podobnie jak wyżej, decydujemy tym razem, czy zaudytowane wiadomości mają być skopiowane do jeszcze jakiejś innej kolejki. Po wybraniu opcji ON pojawia się pole do wpisania nazwy takiej kolejki. Funkcjonalność ta może być pomocna, jeśli chcemy zrobić coś niestandardowego z takimi wiadomościami.
Po zapisaniu konfiguracji, ServiceControl Management utworzy nową instancję oraz uruchomi usługę windows. Przykładowa konfiguracja z użyciem SQL Server Transport może wyglądać tak:
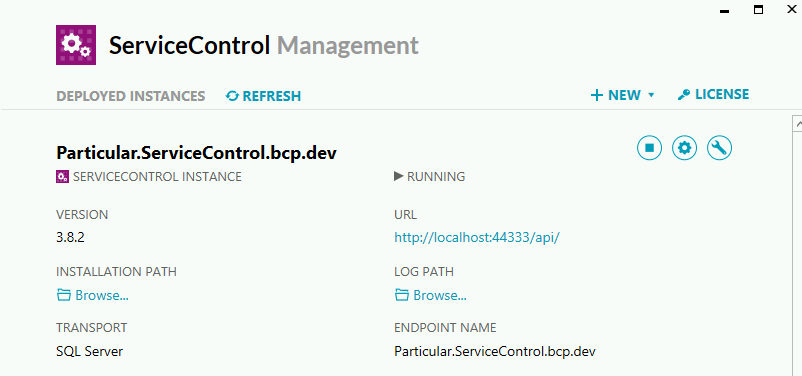
W tym momencie instancja jest gotowa do wykorzystania przez kolejne komponenty Platformy.
ServicePulse
ServicePulse jest aplikacją webową, która korzysta z danych udostępnianych przez ServiceControla, komunikując się z nim poprzez HTTP API. Aby móc skorzystać z funkcjonalności ServicePulsa, trzeba go zainstalować, a następnie wskazać, z którą instancją ServiceControla ma się komunikować.
Instalacja
Podobnie jak w przypadku ServiceControla, instalację ServicePulsa można przeprowadzić co najmniej na trzy sposoby:
- instalując całą Particular Platform, korzystając z dostarczanego instalatora
- instalując samego ServicePulsa, korzystając z dostarczanego instalatora
- instalując samego ServicePulsa, korzystając z dostarczanego instalatora w trybie Quiet
Plik instalacyjny pobieramy ze strony producenta. Opisu instalacji w trybie Quiet szukamy, wpisując w dokumentacji słowo kluczowe Quiet.
W trakcie instalacji należy wskazać:
- port, pod jakim będzie dostępny ServicePulse - hostowany jako usługa windows
- URL do HTTP API ServiceControla
- URL do HTTP API monitoringu ServiceControla - opcją monitoringu zajmiemy się w następnym artykule.
Jeśli w trakcie instalacji pozostawiliśmy domyślny port, to aplikacja dostępna jest pod adresem http://localhost:9090
Wykorzystanie
Zobaczmy teraz, w jaki sposób możemy wykorzystać ServicePulsa w fazie Develop. Załóżmy, że kodujemy logikę NServiceBus Handlera. Piszemy kod i uruchamiamy Endpointa, aby sprawdzić, czy wszystko działa tak, jak powinno. Endpoint przetwarza wiadomość, ale zgłasza informację, że mimo wielu prób (NServiceBus Recoverability) nie jest w stanie jej przetworzyć. Informuje, że wysłał taką zatrutą wiadomość do kolejki z błędami:
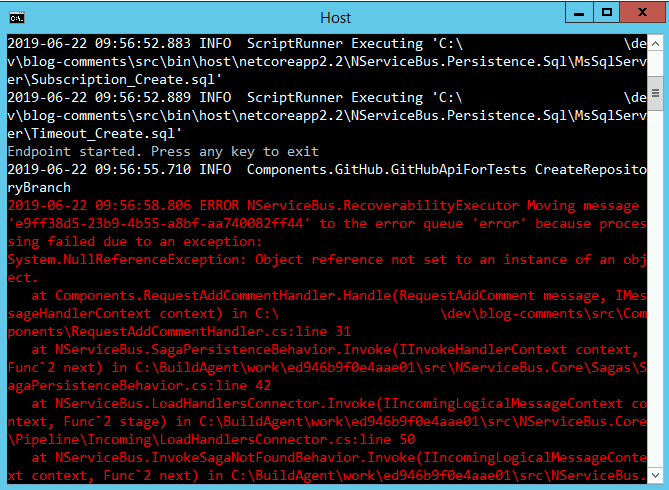
W tym momencie ServiceControl pobiera zatrutą wiadomość z kolejki błędów i wstawia ją do swojej bazy danych. Dostęp do informacji o tej wiadomości udostępnia przez swoje HTTP API.
Przejdźmy przez kolejne kroki obsługi takiej zatrutej wiadomości w ServicePulsie w wersji 1.20.1
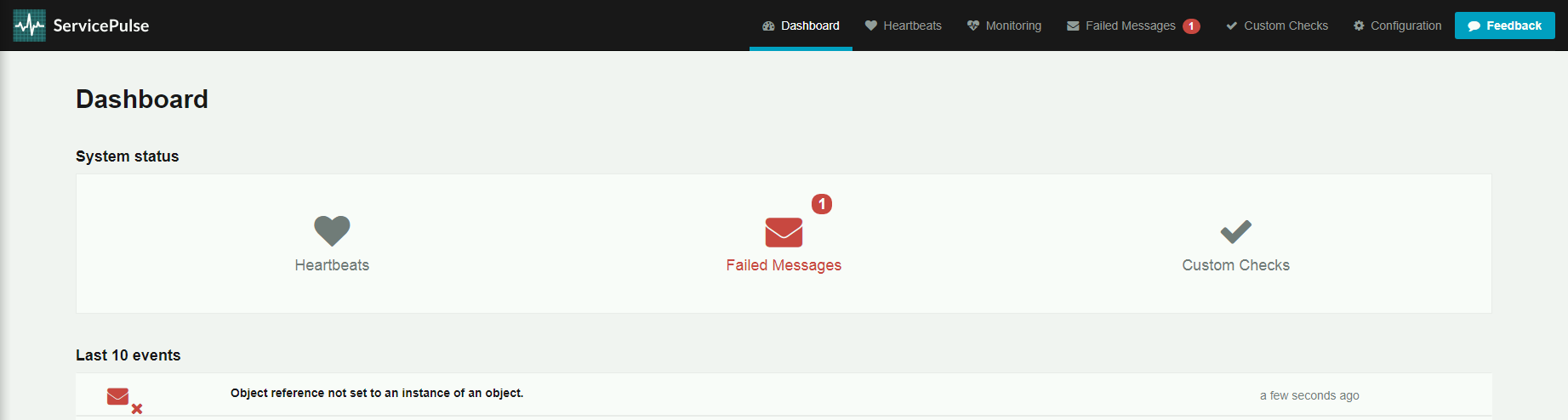
W zakładce Dashboard widzimy informację o nieprzetworzonych wiadomościach.
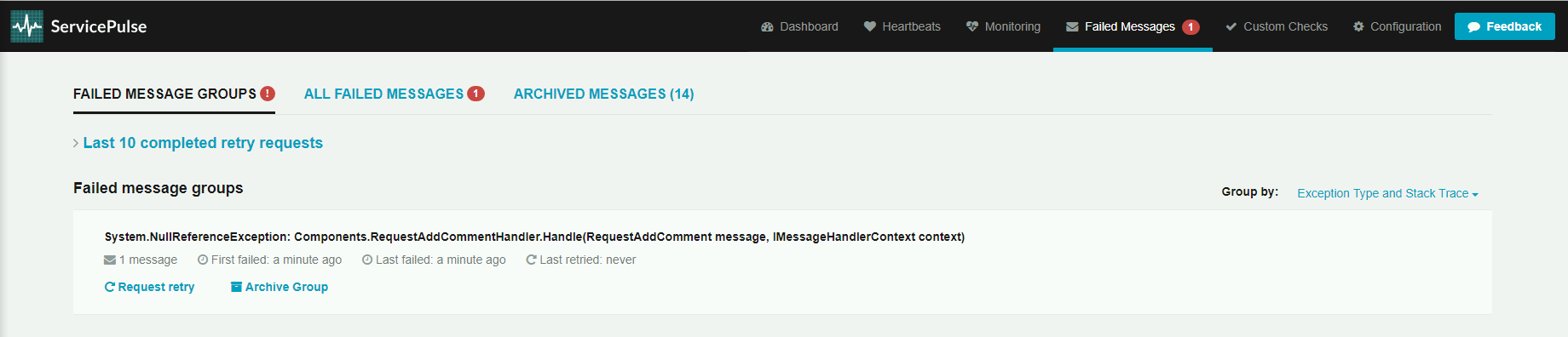
Po kliknięciu w zakładkę Failed Messages pokazują nam się nieprzetworzone wiadomości pogrupowane wg typu wyjątku oraz StackTracea. Funkcjonalność Group by pozwala grupować wiadomości po różnych atrybutach.
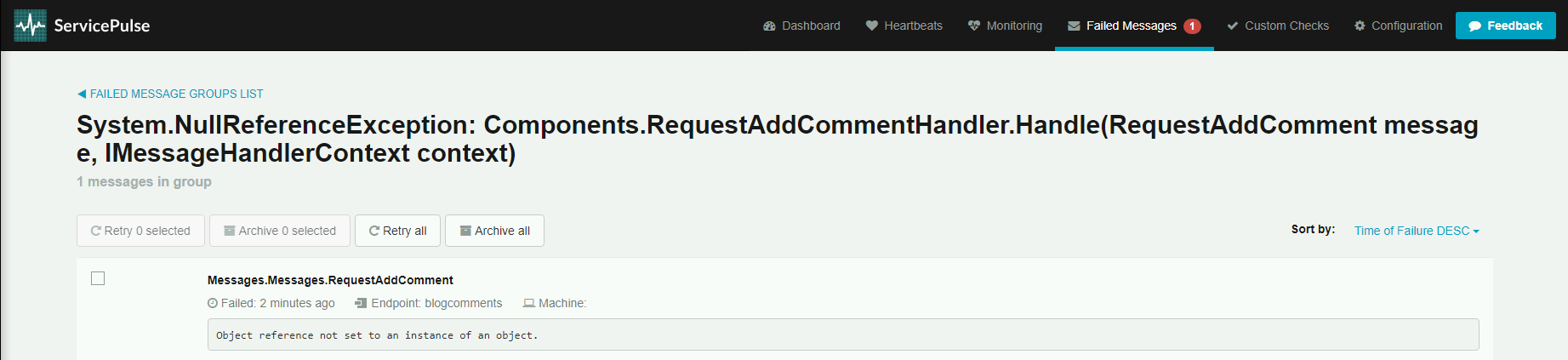
Klikamy w grupę i widzimy listę błędnych wiadomości oraz dodatkowe funkcjonalności:
- Retry selected - przywrócenie wybranych wiadomości do ponownego przetwarzania
- Archive selected - przeniesienie wybranych wiadomości do archiwum
- Retry all - przywrócenie wszystkich wiadomości z grupy do ponownego przetwarzania
- Archive all - przeniesienie wszystkich wiadomości z grupy do archiwum
- Sort by - sortowanie po wybranych atrybutach
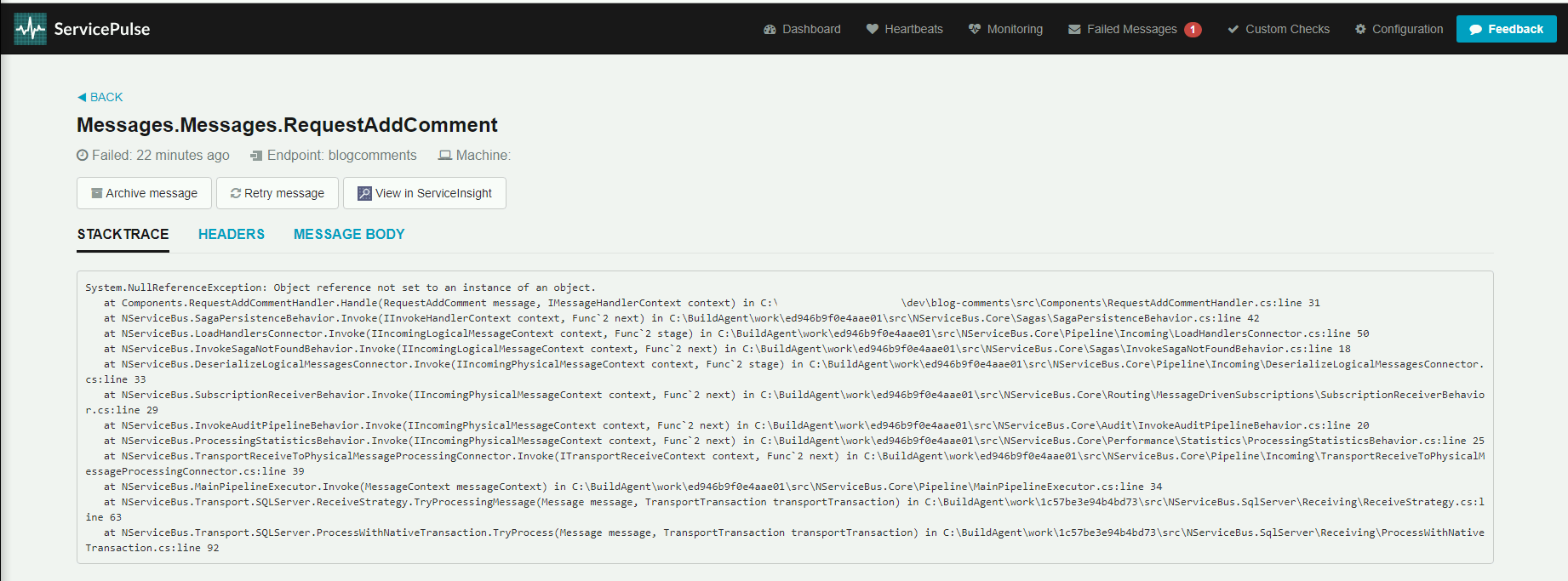
Po kliknięciu na konkretnej wiadomości pokazuje się StackTrace, a także funkcjonalności pozwalające zadziałać na tej konkretnej wiadomości:
- Archive message - przeniesienie wiadomości do archiwum
- Retry message - przywrócenie wiadomości do ponownego przetwarzania
- View in ServiceInsight - otwarcie wiadomości w narzędziu ServiceInsight
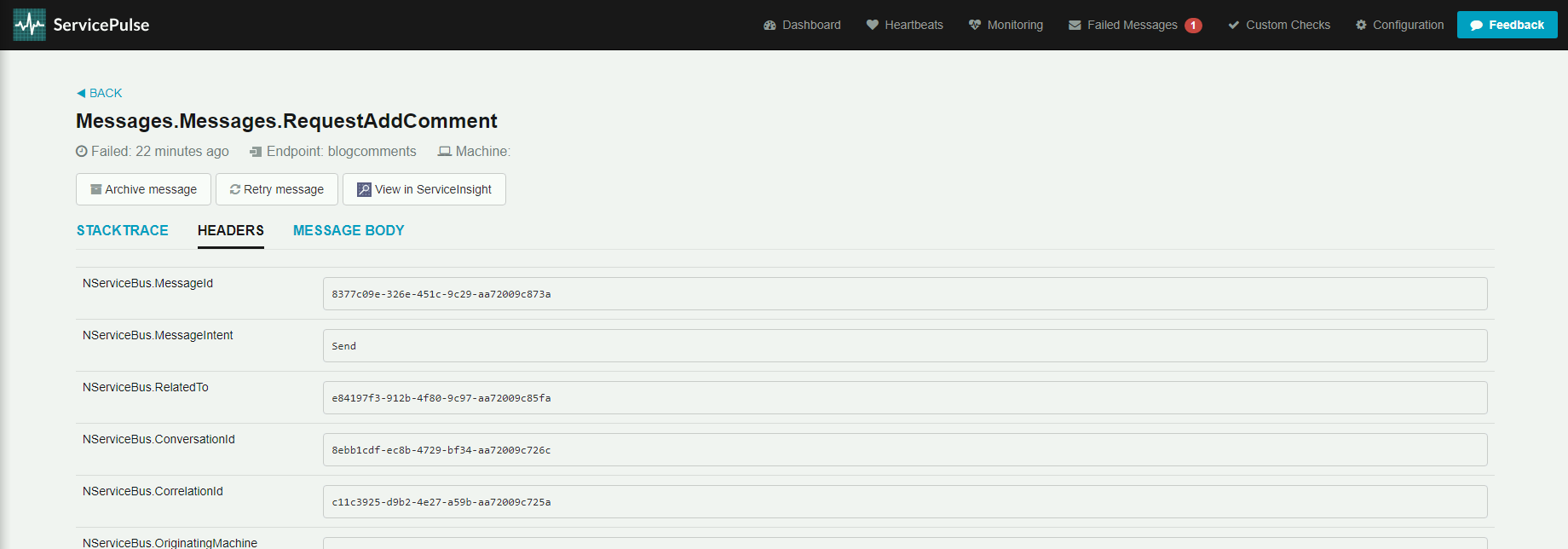
Po przejściu na zakładkę HEADERS widzimy nagłówki wiadomości dołączane przez NServiceBusa.
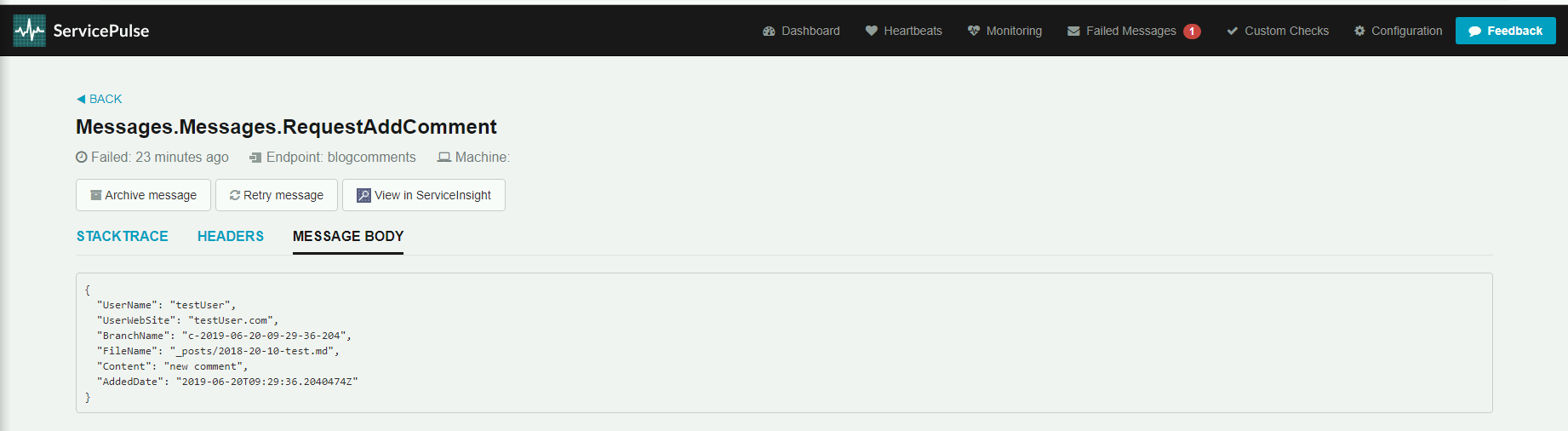
Po przejściu na zakładkę MESSAGE BODY widzimy dane, jakie zawiera wiadomość.
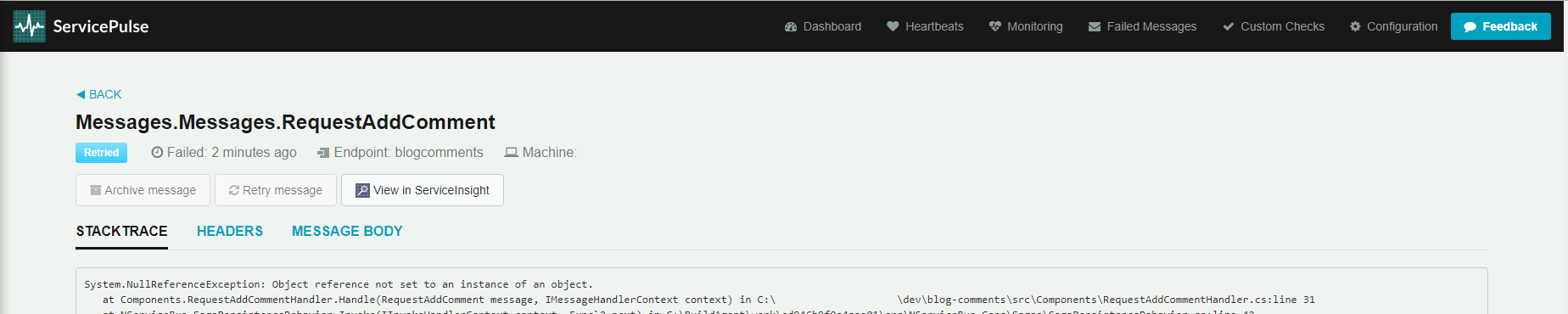
A tak wygląda widok po przywróceniu wiadomości do ponownego przetworzenia. Informuje o tym znacznik Retried. Po kliknięciu w zakładkę Failed Messages przywrócone oraz zarchiwizowane wiadomości znikają z interfejsu użytkownika.
Cały proces obsługi zatrutych wiadomości może wyglądać tak:
- kodujemy funkcjonalność
- generujemy test z danymi, sprawdzając, czy wszystko działa tak, jak powinno
- jeśli nie ma błędów, to przechodzimy do kodowania kolejnej funkcjonalności
- jeśli widzimy błąd, to przechodzimy do ServicePulsa i analizujemy przyczynę błędu
- na tym etapie dużą wartością jest to, że oprócz StackTracea mamy dostęp do danych powiązanych z błędem, co w znacznym stopniu skraca czas namierzenia problemu
- jeśli błąd jest w algorytmie, to poprawiamy kod, uruchamiamy Endpointa i w ServicePulsie przywracanym wiadomość do ponownego przetworzenia
- jeśli błąd jest w danych, to w ServicePulsie archiwizujemy wiadomość i ponownie generujemy test z poprawionymi danymi
Ten sam proces można wykorzystać po wdrożeniu funkcjonalności na środowisko testowe. W tym przypadku środowisko to musi mieć zainstalowaną i skonfigurowaną swoją instancję ServiceControla oraz ServicePulsa.
Pytanie, jakie może się teraz pojawić, to “A co jak korzystam tylko z NServiceBusa?”. W tym przypadku zatrute wiadomości będą czekały na obsługę w kolejce z błędami. W nagłówkach wiadomości dołączanych przez NServiceBusa znajdują się te same informacje, które wyświetla ServicePulse. Dzięki temu dalej możemy analizować przyczynę wystąpienia błędu. Na etapie programowania, wiemy, która kolejka przetwarzała daną wiadomość, więc wiemy też, do której kolejki musimy przenieść wiadomość, aby ponownie ją przetworzyć. Nazwę kolejki źródłowej możemy również odczytać z nagłówka wiadomości. StackTrace błędu możemy również odczytać z logów generowanych przez NServiceBusa. W tym przypadku musimy jednak znaleźć inny sposób, aby fizycznie przenieść wiadomość lub wiadomości do odpowiednich kolejek źródłowych. Sposób ten może być inny w zależności od wybranego transportu. Udogodnieniem jest to, że zespół rozwijający platformę udostępnia skrypty wspomagające takie operacje np.
Możemy też za każdym razem generować nowy przypadek testowy, a zatrute wiadomości usuwać z kolejki. Jest to jednak uciążliwe, w przypadku gdy mamy drobne błędy w środku jakiegoś większego procesu. Poprawianie błędów i przywracanie wiadomości do ponownego przetworzenia jest szybsze niż generowanie całego scenariusza od początku.
Mając ServicePulsa, wspomaganego przez ServiceControla, dostajemy jedną spójną aplikację, z wieloma przydatnymi funkcjonalnościami, działającą tak samo niezależnie od wybranego transportu do przesyłania wiadomości, posiadającą przyjazny interfejs użytkownika. Całość sprawia, że programowanie nowych funkcjonalności staje się szybsze, wygodniejsze i przyjemniejsze.
ServiceInsight
ServiceInsight jest aplikacją desktopową i tak samo jak ServicePulse, korzysta z danych udostępnianych przez ServiceControla. Aby móc skorzystać z funkcjonalności ServiceInsighta trzeba go najpierw zainstalować, a następnie wskazać, z którą instancją ServiceControla ma się komunikować.
Instalacja
Mamy dwie możliwości instalacji:
- instalacja wraz z całą Particular Platform, korzystając z dostarczanego instalatora
- instalacja samego ServiceInsighta, korzystając z dostarczanego instalatora
Tak jak w przypadku pozostałych komponentów, pliki instalacyjne można znaleźć na stronie producenta.
Po pierwszym uruchomieniu aplikacji klikamy w opcję tools -> Connect to ServiceControl, aby wskazać adres URL do HTTP API.
Wykorzystanie
ServiceInsight pozwala przeglądać i analizować przepływ wiadomości wysłanych przez NServiceBusa. Dzięki wizualizacji przepływu umożliwia zrozumienie połączeń pomiędzy poszczególnymi wiadomościami.
Zobaczmy kilka z jego wielu funkcjonalności dla wersji 1.13.0
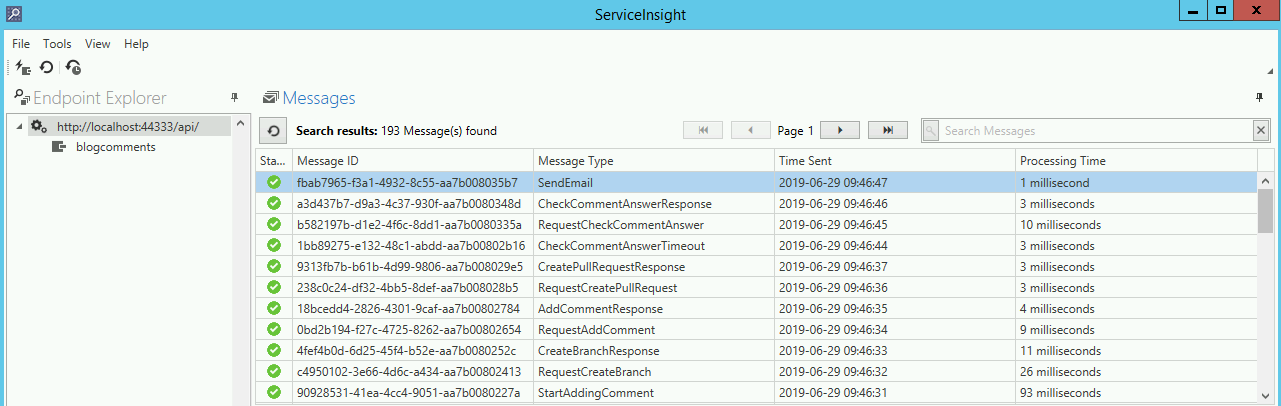
Po przetworzeniu wiadomości przez ServiceControla pojawiają się one na głównym oknie ServiceInsighta. Widzimy na nim, między innymi, takie informacje, jak:
- status wiadomości
- id wiadomości
- typ wiadomości
- czas przesłania wiadomości
- czas od momentu rozpoczęcia przetwarzania wiadomości do jej zakończenia - sortując po tym atrybucie, możemy sprawdzić, które wiadomości przetwarzają się najszybciej, a które najwolniej
Po lewej stronie widzimy listę Endpointów NServiceBusa. W przykładzie jest tylko jeden, ale jakby było ich więcej, to możemy kliknąć na konkretny Endpoint, aby zobaczyć, jakie wiadomości były przetwarzane przez ten konkretny Endpoint.
Bardzo użyteczną opcją jest wyszukiwanie wiadomości po różnych atrybutach, w tym po informacjach zawartych w Body wiadomości. Dzięki temu możemy przeszukiwać historię np. po jakiejś wartości dotyczącej konkretnej danej biznesowej i spróbować namierzyć przyczynę takiego czy innego zachowania systemu.
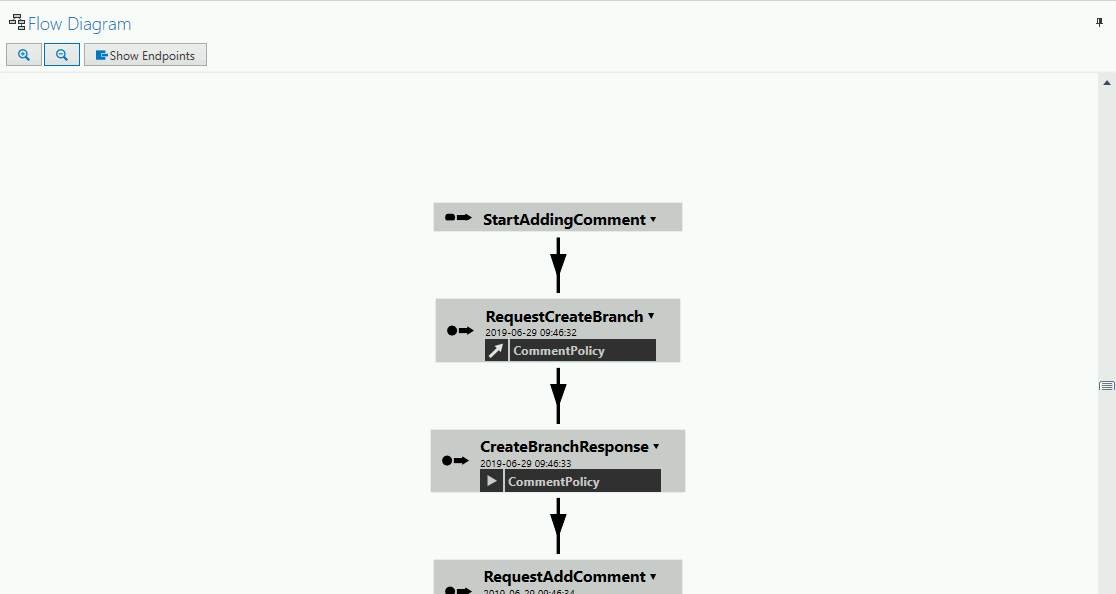
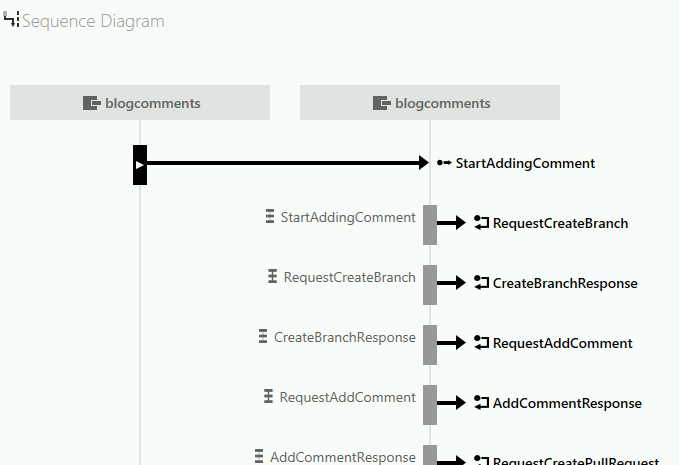
Diagramy Flow i Sequence ułatwiają zrozumienie przepływu, a także powiązań pomiędzy poszczególnymi typami wiadomości.

Body zawiera dane jakie przyszły razem z wiadomością, jakże kluczowe przy analizie przypadku.
Zobaczmy, w jaki sposób możemy przeprowadzić przykładową analizę, dla funkcjonalności, której ostatnim krokiem jest aktualizacja danych prezentowanych na interfejsie użytkownika.
- kodujemy funkcjonalność
- generujemy test z danymi, sprawdzając, czy wszystko działa tak jak powinno
- po zakończeniu przetwarzania żadne wiadomości nie trafiły na kolejkę błędów
- uruchamiamy interfejs użytkownika, aby przekonać się, że dane zaktualizowały się poprawnie
Okazuje się jednak, że przetworzone dane są prezentowane błędnie:
- uruchamiamy ServiceInsighta
- wyszukujemy wiadomości po atrybucie, który uważamy za kluczowy do namierzenia problemu
- sprawdzamy diagramy Flow i Sequence, a także Body poszczególnych wiadomości
Okazuje się, że w logice biznesowej w jednym z Handlerów NServiceBusa nieprawidłowo podstawiliśmy wartości pod zmienne i żaden test jednostkowy nam tego nie wykrył, np.
- w miejsce UserName podstawiliśmy wartość UserEmail
- w miejsce UserEmail podstawiliśmy wartość UserName
Poprawiamy błąd i ponownie generujemy test z danymi, sprawdzając, czy tym razem wszystko działa tak jak powinno.
Jeśli mamy skonfigurowanego ServiceControla na środowisku testowym to tej samej strategii możemy użyć w fazie testów biznesowych, ustawiając w ServiceInsightcie, zainstalowanym na naszej maszynie developerskiej, odpowiedni URL do HTTP API. Różnica jest tylko taka, że tym razem to użytkownicy zgłaszają nam nieprawidłowości w testowanych funkcjonalnościach. Dzięki informacjom udostępnianym przez ServiceInsighta mamy możliwość przeprowadzenia analizy, zwiększając szanse znalezienia przyczyny błędnego zachowania.
“A co jak korzystam tylko z NServiceBusa?”. W tym przypadku historia wszystkich wiadomości będzie znajdować się w zdefiniowanej kolejce audytowej. Jeśli chcemy skorzystać z tych informacji, musimy sami, w jakiś inny sposób, umieć się do nich dostać. Sposób ten zapewne będzie zależał od wybranego transportu. Możemy również logować różne rzeczy do loga lub do bazy danych. Przy zrozumieniu przepływu wiadomości, możemy przeglądać implementację Handlerów, analizując powiązania pomiędzy poszczególnymi klasami.
Podobnie jak w przypadku ServicePulsa, ServiceInsight dostarcza tych wszystkich informacji, sprawiając, że są one dostępne w jednym miejscu. Prezentuje je w przyjaznym interfejsie użytkownika, skracając czas analizy przypadków oraz powiązań pomiędzy poszczególnymi wiadomościami.
Podsumowanie
Używając całej Platformy Particular, mamy do dyspozycji narzędzia, pozwalające efektywnie wytwarzać oprogramowanie w oparciu o ideę Messagingu i Queueingu. Głównym składnikiem platformy jest NServiceBus, którego uzupełnieniem są: ServiceControl, ServicePulse oraz ServiceInsight. W artykule opisałem, w jaki sposób można używać platformy na etapach Develop oraz Test. W następnym artykule zobaczymy, w jaki sposób Particular Service Platform wspomaga obsługę produkcyjnie wdrożonych funkcjonalności.
=